Prometheus内容详解
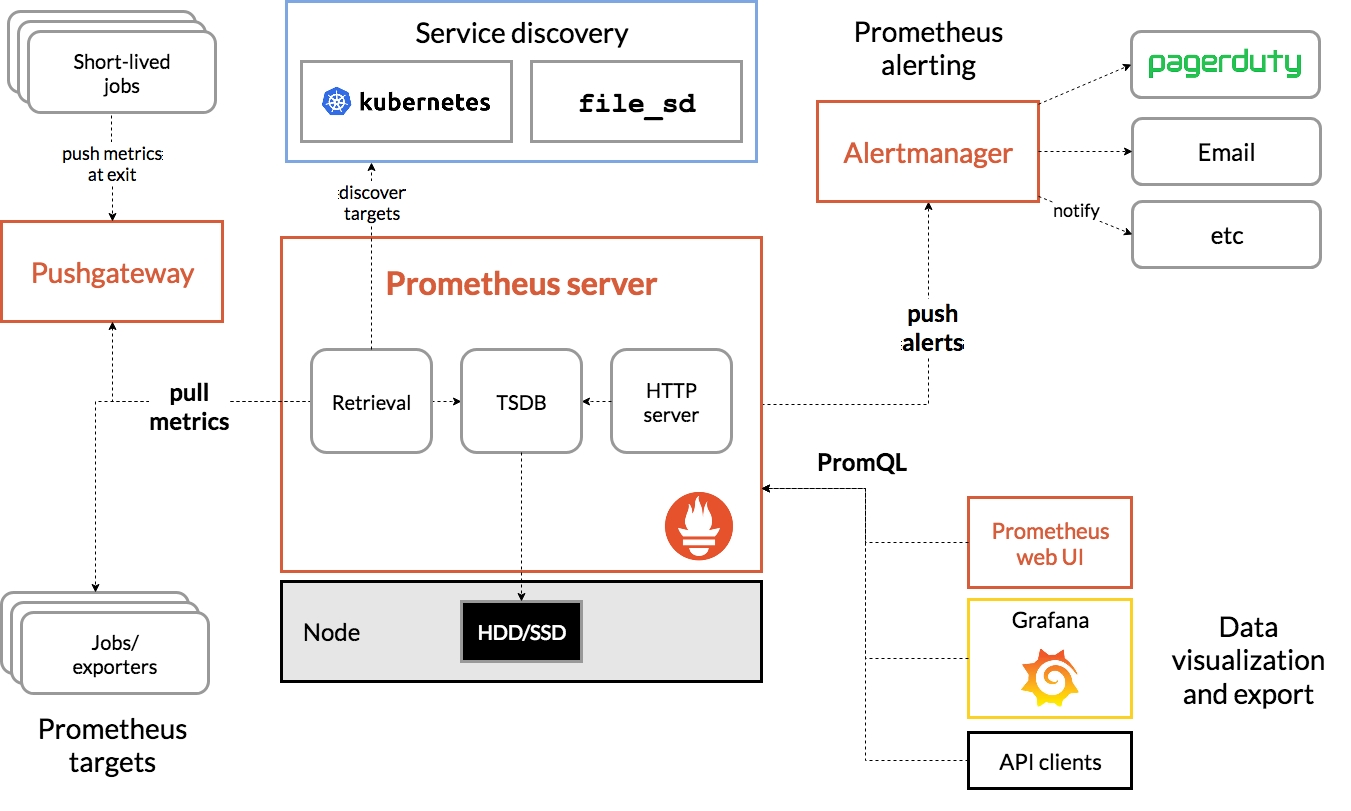
Prometheus 监控系统的架构图
官方文档:https://prometheus.io/docs/introduction/overview/
exporters:
官方/第三方提供的exporters: https://prometheus.io/docs/instrumenting/exporters/
自定义eporters:https://prometheus.io/docs/instrumenting/writing_exporters/
alert:
官方示例:https://prometheus.io/docs/alerting/latest/notification_examples/
第三方提供的alert规则:https://samber.github.io/awesome-prometheus-alerts/
docker部署:https://gitee.com/LightningJie/docker-prometheus/blob/main/docker-compose.yaml
框架模块
Short - lived jobs(短期作业)
这类作业生命周期较短,在退出时将指标数据推送到 Pushgateway。
在数据库场景中,比如每天凌晨执行的数据库日志清理脚本,它在运行结束时,需要将执行过程中的相关指标(如处理的日志文件数量、删除的记录行数等)推送到 Pushgateway。由于其生命周期短,Prometheus 难以直接定时拉取指标,所以采用推送的方式
数据库数据初始化与加载、数据库备份与归档、数据库数据清理与维护、数据库性能测试相关作业、数据库脚本执行作业
Pushgateway
- Prometheus 采用 pull 模式,可能由于不在一个子网或者防火墙原因,导致 Prometheus 无法直接拉取各个 target 数据。
- 在监控业务数据的时候,需要将不同数据汇总888,由 Prometheus 统一收集。
- 当 exporter 不能满足需要时,也可以通过自定义(python、shell、java)监控我们想要的数据。
由于以上原因,不得不使用 pushgateway ,但在使用之前,有必要了解一下它的一些弊端:
- 将多个节点数据汇总到 pushgateway,如果 pushgateway 挂了,受影响比多个 target 大。
- Prometheus 拉取状态 up 只针对 pushgateway,无法做到对每个节点有效。
- Pushgateway 可以持久化推送给它的所有监控数据。
因此,即使你的监控已经下线,prometheus 还会拉取到旧的监控数据,需要手动清理 pushgateway 不要的数据。
作为短期作业推送指标的中间缓存层。它接收短期作业推送过来的指标,并为 Prometheus server 提供拉取指标的接口,解决 Prometheus 难以直接抓取短期作业指标的问题。
短期作业集成相应的客户端库(如 Prometheus 客户端库),在作业内部代码中定义要收集的指标,并在合适的时机(如作业结束时)将这些指标数据推送到 Pushgateway 指定的端点。Pushgateway 会存储这些指标,并为每个推送作业生成唯一的标识(通常基于作业名称和一些标签)。Prometheus 则通过配置文件指定 Pushgateway 的地址和相关作业的标识,定期从 Pushgateway 拉取指标数据,然后将其存储到自身的时间序列数据库(TSDB)中进行后续的分析、告警等操作。
Service discovery(服务发现)
Service discovery 是一种自动发现和管理被监控目标的机制,它允许 Prometheus 动态地识别需要收集指标的目标服务器或服务,而无需手动逐个配置
kubernetes
通过 Kubernetes 进行服务发现,能自动发现 Kubernetes 集群中的服务作为监控目标。
Kubernetes:是一个容器编排系统,主要用于管理和协调多个容器化应用程序在集群环境中的运行。它提供了诸如自动部署、弹性伸缩、服务发现、负载均衡、故障恢复等一系列功能,帮助用户更高效地管理大规模的容器化应用。比如,在一个电商网站的架构中,Kubernetes 可以管理包括前端服务器、后端 API 服务器、数据库服务器等多个不同类型的容器,并根据业务负载自动调整这些容器的数量和分布。
- 数据库资源监控
- Kubernetes 可以将数据库相关的容器、Pod、节点等资源纳入监控范畴,通过 Prometheus 采集这些资源的 CPU、内存、磁盘 I/O、网络流量等指标,帮助运维人员实时了解数据库服务器的资源使用情况,及时发现资源瓶颈,例如当数据库服务器的 CPU 使用率持续过高时,可能意味着查询负载过重,需要进行优化。
- 对于运行在 Kubernetes 集群中的数据库,还能监控其副本数量、健康状态等指标,确保数据库的高可用性和容错能力。比如,当某个数据库 Pod 出现故障时,Kubernetes 可以自动重启或重新调度该 Pod,并通过 Prometheus 及时反馈相关状态变化。
- 数据库性能监测
- Prometheus 结合 Kubernetes 可以对数据库的性能指标进行采集和分析,如数据库的查询执行时间、连接数、事务处理速度等。通过分析这些指标,可以发现数据库性能问题的根源,如慢查询、锁竞争等,从而进行针对性的优化。
- 借助 Kubernetes 的资源隔离和调度机制,可以确保数据库在不同的负载情况下都能获得稳定的资源分配,避免因资源竞争导致的性能波动。同时,Prometheus 可以实时监测资源分配对数据库性能的影响,为调整资源配置提供依据。
- 服务发现与动态配置
- Kubernetes 的服务发现机制能够让 Prometheus 自动发现新部署的数据库实例,无需手动配置监控目标。当在 Kubernetes 集群中新增或删除数据库 Pod 时,Prometheus 可以及时更新监控目标列表,保证监控的连续性和完整性。
- 通过 Kubernetes 的配置管理功能,可以方便地为数据库应用配置不同的监控参数和告警规则。例如,根据不同的数据库类型、业务场景或性能要求,为 Prometheus 配置相应的指标采集频率、告警阈值等,实现精细化的监控和管理。
- 数据库集群管理
- 在数据库集群环境中,Kubernetes 可以协调数据库节点之间的通信和数据同步,确保集群的一致性和稳定性。Prometheus 可以监控集群的关键指标,如节点间的心跳、数据复制延迟等,帮助运维人员及时发现集群中的异常情况。
- 当数据库集群需要进行扩展或收缩时,Kubernetes 可以根据预设的规则自动调整集群规模,并通过 Prometheus 提供的指标数据来评估扩展或收缩的效果,确保集群性能始终满足业务需求。
核心概念
- Pod:Kubernetes 中最小的可部署和可管理的计算单元,它可以包含一个或多个紧密相关的容器。这些容器共享网络命名空间和存储卷,它们在同一个 Pod 中可以方便地进行通信和协作。例如,一个 Web 应用容器和一个数据库容器可以放在同一个 Pod 中,Web 应用容器通过本地网络访问数据库容器。
- Service:定义了一组 Pod 的逻辑集合以及访问它们的策略。Service 提供了一个稳定的 IP 地址和端口,使得其他组件可以通过这个固定的地址来访问 Pod,而无需关心 Pod 的实际 IP 地址和它们的动态变化。
- Deployment:用于描述应用程序的部署方式和策略,包括如何创建、更新和扩展 Pod。通过 Deployment,可以方便地管理应用程序的版本升级、回滚等操作,确保应用程序按照期望的状态运行。例如,你可以通过修改 Deployment 的配置来更新应用程序的版本,Kubernetes 会自动按照指定的策略进行升级。
- Namespace:提供了一种将集群资源划分为不同逻辑隔离空间的方式。不同 Namespace 中的资源名称可以相同,这样可以在同一个集群中为不同的团队、项目或环境创建独立的资源空间,实现资源的隔离和管理。
工作原理
- 资源管理:Kubernetes 通过控制平面来管理集群中的资源。控制平面会根据用户定义的资源需求和策略,将 Pod 调度到合适的工作节点上运行。同时,控制平面还会监控 Pod 的运行状态,确保它们始终处于期望的状态。如果某个 Pod 出现故障,控制平面会自动重新调度该 Pod 到其他可用节点上。
- 服务发现与负载均衡:Service 通过标签选择器来关联后端的 Pod,并为这些 Pod 提供一个统一的访问入口。当客户端发送请求到 Service 时,Service 会根据负载均衡算法将请求分发到后端的 Pod 上。Kubernetes 支持多种负载均衡算法,如轮询、加权轮询等,以满足不同应用场景的需求。
- 自动扩展:Kubernetes 可以根据应用程序的负载情况自动扩展或收缩 Pod 的数量。通过使用 Horizontal Pod Autoscaler(HPA),可以根据 CPU 使用率、内存使用率等指标来自动调整 Deployment 中 Pod 的副本数量。例如,当应用程序的负载增加时,HPA 会自动增加 Pod 的数量,以提高应用程序的处理能力;当负载降低时,HPA 会自动减少 Pod 的数量,节省资源。
关键组件
- etcd:它是一个高可用的键值对存储系统,用于保存 Kubernetes 集群的所有配置信息和状态数据。例如,集群中各个节点的信息、Pod 的定义、Service 的配置等都存储在 etcd 中。etcd 确保这些数据的一致性和可靠性,为 Kubernetes 集群的正常运行提供了基础支撑。
- kube - apiserver:作为 Kubernetes 的核心组件,它提供了 RESTful API 接口,是集群内外各个组件与 Kubernetes 集群进行交互的唯一入口。无论是用户通过命令行工具 kubectl,还是其他自动化工具,都需要通过 kube - apiserver 来提交请求,实现对集群资源的管理,如创建、删除、更新 Pod、Service 等操作。
- kube - scheduler:负责将 Pod 分配到集群中的合适节点上运行。它会根据一系列的调度算法和策略,考虑节点的资源状况(如 CPU、内存)、Pod 的资源需求、节点的亲和性和反亲和性等因素,以确保 Pod 能够在满足其要求的节点上高效运行。
- kube - controller - manager:包含多个控制器,这些控制器负责管理集群中各种资源的状态,确保实际状态与用户定义的期望状态一致。例如,副本控制器(Replica Controller)用于确保指定数量的 Pod 副本始终在运行;节点控制器(Node Controller)负责监控节点的状态,当节点出现故障时进行相应的处理。
- kube - proxy:运行在每个节点上,主要负责实现 Service 的网络代理和负载均衡功能。它会在节点上设置 iptables 规则或使用其他网络代理方式,将发往 Service 的流量转发到后端实际的 Pod 上,从而实现对 Pod 的访问和负载均衡。
监控与日志
- 监控:Kubernetes 提供了多种监控方式,通过集成 Prometheus、Grafana 等监控工具,可以对集群的资源使用情况(如 CPU、内存、网络流量)、Pod 和容器的运行状态、应用程序的性能指标等进行实时监控和分析。用户可以通过监控数据及时发现集群中的问题,并进行相应的调整和优化。
- 日志:容器内的日志可以通过多种方式进行收集和管理,如使用 Fluentd、Elasticsearch 和 Kibana(EFK)组合等。这些工具可以将容器的日志收集起来,进行集中存储和分析,方便用户查看和排查应用程序的故障和问题。
实际应用场景
- 微服务架构:Kubernetes 非常适合用于管理微服务架构的应用程序。每个微服务可以被打包成一个容器,并通过 Kubernetes 进行部署、扩展和管理。Kubernetes 可以方便地实现微服务之间的通信、负载均衡和服务发现,使得微服务架构的应用程序更加易于维护和扩展。
- 持续集成与持续部署(CI/CD):Kubernetes 可以与 CI/CD 工具集成,实现应用程序的自动化部署和更新。当开发人员提交代码后,CI/CD 工具可以自动构建容器镜像,并将其部署到 Kubernetes 集群中。通过使用 Deployment 和相关的更新策略,可以实现应用程序的快速迭代和上线。
- 云原生应用开发:Kubernetes 是云原生应用开发的核心技术之一。它提供了一个弹性、可扩展和高可用的平台,使得开发人员可以专注于应用程序的业务逻辑,而无需关心底层的基础设施管理。云原生应用可以充分利用 Kubernetes 的特性,如容器化、自动化部署和服务发现,以实现快速开发、部署和运维。
file_sd
基于文件的服务发现机制,通过读取配置文件来确定监控目标。file_sd通过指定一个或多个包含目标信息的文件,Prometheus 会定期读取这些文件,解析其中的目标配置,并根据配置动态地添加或删除监控目标。这些文件通常采用 JSON 或 YAML 格式来描述目标的相关信息,如目标的地址、端口、标签等。
配置示例
假设你有一个 Kubernetes 集群,其中有几个需要监控的应用服务,你可以使用file_sd来配置 Prometheus 对这些服务进行监控。以下是一个简单的 YAML 格式的file_sd配置示例:
1 | - job_name: 'kubernetes - services' |
在上述配置中,job_name定义了监控任务的名称,file_sd_configs下的files字段指定了包含目标信息的文件路径,refresh_interval表示 Prometheus 读取文件的时间间隔,这里设置为 10 秒。
接下来是kubernetes - services - targets.yaml文件的内容示例:
1 | - targets: ['10.0.0.1:8080', '10.0.0.2:8080'] |
这个文件中定义了两个监控目标组。第一个目标组包含两个目标,地址分别是10.0.0.1:8080和10.0.0.2:8080,它们都属于名为my - app的应用,并且运行在prod环境中。第二个目标组只有一个目标10.0.0.3:9090,属于another - app应用,运行在test环境中。
当 Prometheus 启动后,它会按照配置的refresh_interval定期读取kubernetes - services - targets.yaml文件,根据其中的内容发现并监控这些目标。如果文件中的目标信息发生变化,Prometheus 会自动更新监控目标,无需手动重启 Prometheus 服务。
Prometheus server
Retrieval
- 功能:该模块是 Prometheus Server 与各种数据源之间的桥梁,负责从 Pushgateway、Jobs/exporters 等目标拉取指标数据。它支持多种数据采集方式,以适应不同的应用场景和技术架构。
- 工作原理:
- 配置解析:首先,Retrieval 模块会读取 Prometheus Server 的配置文件,其中定义了各种 Job 和 Target 的信息。Job 是一组相关 Target 的集合,每个 Target 都对应一个具体的数据源,例如一个运行着 Exporter 的服务器地址和端口。
- 定时拉取:根据配置的时间间隔(默认为 15 秒),Retrieval 模块会为每个 Target 创建一个 HTTP 请求,向其暴露的指标端点发送请求以获取数据。对于 Pushgateway,它会从指定的 Pushgateway 地址拉取由客户端主动推送过来的数据;对于 Jobs/exporters,它会按照配置的目标地址和端口,向相应的 Exporter 发送请求,Exporter 则会将其所监控的应用程序或系统的指标数据以 Prometheus 特定的格式返回。
- 数据处理:接收到数据后,Retrieval 模块会对数据进行初步的处理和验证,确保数据的格式正确且符合 Prometheus 的规范。例如,它会检查数据中的指标名称、标签是否合法,时间戳是否准确等。如果数据存在问题,会记录相应的错误信息,并根据配置决定是否继续处理或丢弃该数据。
- 作用:通过定期从各个数据源拉取指标数据,Retrieval 模块为 Prometheus Server 提供了实时、准确的监控数据,是整个监控系统能够正常运行的基础。它确保了 Prometheus 能够及时获取到系统中各个组件的运行状态信息,为后续的数据分析、告警以及可视化展示提供了数据支持。
TSDB(Time Series Database,时间序列数据库)
- 功能:TSDB 是 Prometheus Server 用于存储时间序列指标数据的核心模块,它以高效、紧凑的方式存储大量的监控数据,并支持快速的数据查询和检索,以便用户能够及时获取到历史数据进行分析和比较。
- 工作原理:
- 数据结构:在 TSDB 中,时间序列数据以键值对的形式存储,其中键由指标名称和一组标签组成,用于唯一标识一个时间序列,值则是一系列的时间戳 - 值对,表示该时间序列在不同时间点上的取值。例如,对于一个监控服务器 CPU 使用率的指标,指标名称可能是 “cpu_usage_percentage”,标签可能包括 “instance”(服务器实例名称)、“job”(所属的 Job 名称)等,而时间戳 - 值对则记录了不同时间点上 CPU 的使用率。
- 数据存储:TSDB 将数据分为多个块(Block)进行存储,每个块包含了一定时间范围内的数据。默认情况下,每个块的时间范围是 2 小时。数据在写入块时,会先进行压缩处理,以减少存储空间占用。Prometheus 使用了多种压缩算法,如 Delta-of-Deltas 编码等,对数据进行高效压缩。同时,为了提高查询性能,TSDB 还会为每个块建立索引,包括时间索引和标签索引,使得在查询数据时能够快速定位到包含所需数据的块。
- 数据查询:当收到查询请求时,TSDB 会根据查询条件解析出需要查询的时间范围和指标名称、标签等信息。然后,它会利用索引快速定位到包含相关数据的块,并从这些块中读取数据。在读取数据后,TSDB 会根据查询要求对数据进行进一步的处理,如聚合、过滤等操作,最后将处理结果返回给查询和告警模块或其他请求方。
- 作用:TSDB 的存在使得 Prometheus Server 能够存储大量的历史监控数据,为用户提供了强大的数据分析和追溯能力。用户可以通过查询 TSDB 获取系统在过去一段时间内的运行趋势,分析性能瓶颈,以及检测异常行为。同时,它的高效存储和查询机制保证了在处理大规模数据时,Prometheus 仍然能够保持较高的性能和响应速度。
HTTP server
- 功能:HTTP server 是 Prometheus Server 对外提供服务的接口,它通过 HTTP 协议提供了一系列的 API 和 Web 界面,用于 Prometheus web UI、API clients 等进行数据访问和交互。用户可以通过 HTTP 请求发送查询语句、获取监控数据、查看系统状态,以及进行一些配置管理操作等。
- 工作原理:
- 请求监听:HTTP server 在启动时会绑定到指定的端口(默认为 9090),开始监听来自客户端的 HTTP 请求。它使用了 Go 语言的标准 HTTP 库来处理网络连接和请求解析。
- 路由处理:当收到一个 HTTP 请求时,HTTP server 会根据请求的 URL 路径和方法来确定对应的处理函数。例如,对于以 “/api/v1/query” 开头的请求,通常是用于执行 PromQL 查询的 API,服务器会调用相应的查询处理函数;对于以 “/graph” 开头的请求,则会返回 Prometheus web UI 的图表页面。
- 查询处理:如果是一个查询请求,HTTP server 会从请求中解析出 PromQL 查询语句,并将其传递给查询引擎进行处理。查询引擎会与 TSDB 进行交互,获取所需的数据,并对数据进行计算和处理。处理完成后,HTTP server 会将结果以 JSON 格式返回给客户端。
- Web 界面渲染:对于 Prometheus web UI 的请求,HTTP server 会返回相应的 HTML、CSS 和 JavaScript 文件,这些文件在客户端浏览器中渲染后,会呈现出一个可视化的监控界面。用户可以在这个界面上通过图形化的方式查看各种指标数据、创建自定义的仪表盘,以及进行数据过滤和分析等操作。
- 作用:HTTP server 为 Prometheus Server 提供了一个便捷的交互接口,使得用户和其他系统能够方便地与 Prometheus 进行集成和通信。通过这个接口,用户可以使用各种工具和客户端来访问监控数据,进行数据分析和可视化展示。同时,它也支持第三方应用程序通过 API 与 Prometheus 进行交互,实现自动化的监控和管理任务,大大提高了 Prometheus 的可扩展性和实用性。
Exporter
Exporter 是 Prometheus 生态系统中的一个关键组件,用于将各种不同系统、服务或应用程序的指标数据转换为 Prometheus 能够识别和处理的格式,并提供给 Prometheus Server 进行采集和监控。
Exporter 的主要作用是将原本不兼容 Prometheus 数据格式的指标数据进行转换和适配。不同的系统和服务通常使用各自特定的方式来表示性能指标和运行状态信息,Exporter 就是一个桥梁,它能够理解这些不同来源的数据,并将其重新格式化为 Prometheus 所使用的时间序列数据格式,这样 Prometheus Server 就可以方便地从 Exporter 拉取数据进行统一的存储、分析和展示。
工作原理
数据收集:Exporter 通过与目标系统或服务进行交互来收集指标数据。这可能涉及到使用各种不同的技术和协议,具体取决于被监控的对象。例如,对于操作系统,Exporter 可能会使用系统命令或特定的系统接口来获取 CPU 使用率、内存使用量、磁盘 I/O 等信息;对于数据库,Exporter 可能会通过数据库的客户端库执行查询来获取数据库的性能指标,如查询执行时间、连接数、缓存命中率等。
格式转换:收集到数据后,Exporter 会将其转换为 Prometheus 的格式。在 Prometheus 中,数据以指标名称和一组标签的形式表示,每个指标可以有多个时间戳 - 值对,表示不同时间点上的指标值。Exporter 会将收集到的各种指标数据映射到 Prometheus 的指标体系中,并为每个指标添加适当的标签,以便在 Prometheus 中进行区分和查询。例如,一个监控服务器 CPU 使用率的 Exporter 可能会将数据转换为名为 “cpu_usage_percentage” 的指标,并添加 “instance”(服务器实例名称)、“job”(所属的 Job 名称)等标签,然后按照 Prometheus 的协议将数据暴露在一个 HTTP 端点上。
数据暴露:Exporter 会在本地启动一个 HTTP 服务器,默认情况下会在某个特定的端口上监听请求(例如,许多 Exporter 默认使用 9100 端口)。Prometheus Server 通过向 Exporter 的 HTTP 端点发送 HTTP 请求来拉取指标数据。Exporter 在接收到请求后,会将转换后的数据以 Prometheus 特定的文本格式返回给 Prometheus Server,这个格式通常被称为 “Prometheus exposition format”。
常见类型
节点 Exporter:用于收集服务器节点的各种系统指标,如 CPU、内存、磁盘、网络等使用情况。它是 Prometheus 监控基础设施中最常用的 Exporter 之一,通过收集这些底层系统指标,可以帮助管理员了解服务器的资源使用状况,及时发现潜在的性能问题。
应用程序 Exporter:针对特定的应用程序或服务进行指标收集的 Exporter。例如,MySQL Exporter 用于收集 MySQL 数据库的性能指标,包括查询执行时间、缓存命中率、事务处理等;Redis Exporter 用于监控 Redis 缓存服务器的指标,如内存使用、键空间信息、连接数等。这些 Exporter 能够深入了解应用程序的运行状态,帮助开发人员和运维人员优化应用程序性能、诊断问题。
中间件 Exporter:用于监控各种中间件技术的指标,如 Kafka Exporter 用于收集 Kafka 消息队列的相关指标,如消息吞吐量、消费者滞后情况、分区状态等;Nginx Exporter 用于监控 Nginx 服务器的访问日志、连接数、请求处理等指标。通过对中间件的监控,可以确保其稳定运行,保障整个系统的可靠性和性能。
分类
直接采集型
这类 Exporter 自身就集成了能与 Prometheus 交互、提供目标(Target)数据的功能模块 。就像 cAdvisor、Kubernetes,它们自身具备专门的端点(类似提供数据的接口),可直接把内部运行状态等相关监控数据发送给 Prometheus。比如 cAdvisor 能实时采集容器的资源使用情况(CPU、内存等),然后传递给 Prometheus,不需要额外复杂的转换或中间环节。
间接采集型
当原始监控目标(如 Linux 系统、某些数据库、HTTP 应用等)自身没有直接适配 Prometheus 的能力时,就得借助 Prometheus 提供的 Client Library(客户端库)来编写专门的采集程序 ,也就是 Exporter。像 Linux 系统,得安装 Node Exporter 这个程序,它会去收集 Linux 系统层面的指标(如 CPU 使用率、磁盘 I/O 等),整理成 Prometheus 能识别的格式后再提供过去。
自定义 Exporter
在实际应用中,除了使用官方和社区提供的各种 Exporter 外,用户还可以根据自己的需求开发自定义的 Exporter。当遇到一些特殊的系统或服务,没有现成的 Exporter 可用时,或者需要收集一些特定的、非标准的指标数据时,就可以通过编写自定义 Exporter 来实现。自定义 Exporter 可以使用各种编程语言来开发,只要能够实现数据收集、格式转换和 HTTP 接口暴露等功能即可。例如,可以使用 Python 的 Flask 框架或 Go 语言的标准 HTTP 库来创建一个简单的自定义 Exporter,收集特定业务系统的指标并提供给 Prometheus 进行监控。
blackbox_exporter
- 功能概述:blackbox_exporter 是 Prometheus 生态系统中的一个工具,主要用于对网络服务进行黑盒监控。它通过模拟各种网络请求来检查目标服务的可达性和性能,而无需了解目标服务的内部实现细节。
- 工作原理:它支持多种探测协议,包括 ICMP、TCP、HTTP、HTTPS、DNS 等。例如,当使用 HTTP 协议进行探测时,它会向指定的 URL 发送 HTTP 请求,并根据响应来判断服务是否正常运行,同时收集诸如响应时间、状态码等指标。对于 ICMP 探测,它会发送 ping 包来检查目标主机是否可达以及往返时间。
- 应用场景:可以用于监控网站的可用性,确保用户能够正常访问网页;也能用于检测网络设备的连通性,及时发现网络故障;还可对各种基于网络协议的服务进行健康检查,保障服务的稳定性。
consul_exporter
- 功能概述:consul_exporter 是专门为 Consul 服务发现和配置管理系统设计的一个工具,用于将 Consul 中的相关信息转化为 Prometheus 能够理解和处理的指标。
- 工作原理:它通过 Consul 的 API 获取各种数据,包括服务注册信息、节点状态、健康检查结果等。然后将这些信息转换为 Prometheus 的指标格式,例如,将服务的注册数量、健康服务的数量、节点的负载等信息转化为相应的数值指标,以便 Prometheus 进行收集和分析。
- 应用场景:在微服务架构中,当使用 Consul 进行服务发现和健康管理时,consul_exporter 可以帮助运维人员监控 Consul 集群的运行状态,了解各个服务的注册和健康情况,及时发现服务故障或异常,确保整个微服务系统的稳定运行。
graphite_exporter
- 功能概述:graphite_exporter 的作用是在 Graphite 和 Prometheus 之间搭建一座桥梁,使 Prometheus 能够获取和处理 Graphite 中存储的时间序列数据。
- 工作原理:它通过与 Graphite 的 API 进行交互,按照一定的规则将 Graphite 中的数据转换为 Prometheus 的指标格式。例如,它会将 Graphite 中以特定路径和命名规则存储的指标数据,转换为 Prometheus 中具有明确标签和值的指标,然后暴露给 Prometheus 进行抓取。
- 应用场景:当企业已经在使用 Graphite 进行数据存储和可视化,同时又希望引入 Prometheus 进行更强大的数据分析和告警功能时,graphite_exporter 就可以发挥作用,实现数据的共享和整合,避免重复采集数据,保护已有的数据资产。
memcached_exporter
- 功能概述:memcached_exporter 是用于监控 Memcached 内存缓存系统的工具,它能够收集 Memcached 服务器的详细运行指标,为运维人员提供关于缓存系统的运行状态信息。(Memcached 是一个开源的高性能分布式内存对象缓存系统,常用于动态 Web 应用程序中以减轻数据库负载,提高系统性能。)
- 工作原理:它通过与 Memcached 服务器建立连接,发送特定的命令来获取各种统计信息,如缓存项的数量、缓存命中率、内存使用情况、连接数、请求速率等。然后将这些信息转换为 Prometheus 可识别的指标,以便进行存储和分析。
- 应用场景:在应用程序中使用 Memcached 作为缓存来提高性能时,memcached_exporter 可以帮助运维人员实时监控缓存的使用情况,及时发现缓存击穿、缓存雪崩等潜在问题,以便采取相应的措施进行优化,如调整缓存策略、增加缓存容量等,确保缓存系统能够高效稳定地运行,提升整个应用程序的性能和响应速度。
mysqld_exporter
- 功能概述:mysqld_exporter 是专门为 MySQL 数据库设计的指标收集工具,它能够深入挖掘 MySQL 数据库的运行状态和性能指标,为数据库管理员和运维人员提供全面的监控数据。
- 工作原理:它通过连接到 MySQL 数据库,执行一系列的查询语句来获取各种指标信息。这些指标包括数据库的连接数、查询执行时间、缓存使用情况(如查询缓存、InnoDB 缓冲池等)、事务处理情况、索引使用情况、磁盘 I/O 等。然后将这些信息转换为 Prometheus 的指标格式,方便 Prometheus 进行采集和分析。
- 应用场景:在数据库管理中,mysqld_exporter 是一个非常重要的工具。它可以帮助 DBA 及时发现数据库的性能瓶颈,如查询执行缓慢、缓存命中率低、磁盘 I/O 过高导致的性能下降等问题。通过对这些指标的分析,DBA 可以采取相应的优化措施,如优化查询语句、调整数据库配置参数、添加索引等,以提高数据库的性能和稳定性,确保业务系统能够正常运行。
node_exporter
- 功能概述:node_exporter 是 Prometheus 生态中用于收集服务器节点系统指标的关键组件,它能够提供关于服务器硬件和操作系统层面的详细信息。
- 工作原理:它通过与操作系统的底层接口进行交互,收集各种系统指标。例如,通过读取 /proc 文件系统(在 Linux 系统中)获取 CPU 使用率、内存使用情况、磁盘 I/O 统计、进程信息等。对于系统的网络接口,它会收集网络流量数据,包括发送和接收的字节数、数据包数量等。此外,还能获取系统的负载平均值、开机时间等信息,并将这些信息转换为 Prometheus 可识别的指标格式进行暴露。
- 应用场景:以一个大型电商网站为例,其背后的服务器集群可能包含多个服务器节点,在服务器运维中,node_exporter 是必不可少的工具。它可以帮助运维人员全面了解服务器的运行状态,及时发现服务器的性能问题,如 CPU 过载、内存泄漏、磁盘空间不足、网络拥堵等。通过对这些指标的监控和分析,运维人员可以提前采取措施进行故障排除和性能优化,保障服务器的稳定运行,避免因系统故障导致的业务中断。
statsd_exporter
功能概述:statsd_exporter 主要用于将 StatsD 收集的指标数据转换为 Prometheus 能够处理的格式,从而实现将 StatsD 的数据纳入 Prometheus 的监控体系。
工作原理:它监听 StatsD 发送的数据,按照 StatsD 的协议解析数据,并将其转换为 Prometheus 的指标。StatsD 通常收集应用程序的各种指标,如计数器(用于统计事件发生的次数)、计时器(用于记录操作的执行时间)、直方图(用于统计数据的分布情况)等。statsd_exporter 会将这些不同类型的指标转换为 Prometheus 中对应的指标类型,并添加适当的标签,以便 Prometheus 进行分类和存储。
应用场景:在一些应用程序中,已经使用 StatsD 进行指标收集,而希望利用 Prometheus 强大的查询、告警和可视化功能时,statsd_exporter 就可以发挥作用。它可以将 StatsD 收集到的应用程序性能指标,如接口调用次数、响应时间分布等,提供给 Prometheus 进行进一步的分析和处理,帮助开发人员和运维人员更好地了解应用程序的运行状况,及时发现性能问题并进行优化。
StatsD 是一个用于实时收集和汇总应用程序统计数据的工具,通常用于监控系统性能和应用程序行为。以下是关于它的详细介绍:
特点
- 轻量级:StatsD 的设计目标是轻量级和高效,它可以快速处理大量的统计数据,而不会给应用程序带来过多的性能开销。
- 可扩展:支持插件扩展机制,用户可以根据自己的需求开发自定义插件,以扩展 StatsD 的功能,例如添加新的数据收集器或聚合器。
- 支持多种数据类型:能够处理多种类型的统计数据,包括计数器(Counter)、计量器(Gauge)、直方图(Histogram)和分布(Distribution)等,满足不同场景下的统计需求。
- 与其他系统集成性好:可以很方便地与其他监控和数据分析系统集成,如 Graphite、InfluxDB 等,将收集到的数据进行存储、可视化和进一步分析。
工作原理
- 数据收集:StatsD 通过 UDP 协议接收来自应用程序发送的统计数据。应用程序在运行过程中,根据需要向 StatsD 发送各种类型的统计信息,例如,记录某个函数被调用的次数、某个操作的执行时间等。
- 数据处理:StatsD 接收到数据后,会按照一定的规则对数据进行处理和汇总。它可以在内存中对数据进行实时聚合,例如计算平均值、最大值、最小值等,并根据配置的时间间隔将汇总后的数据发送到后端的存储或分析系统。
- 数据存储与展示:StatsD 本身并不存储数据,而是将处理后的数据转发给其他数据存储系统,如 Graphite。这些存储系统会将数据持久化保存,并提供相应的可视化工具,以便用户直观地查看和分析统计数据的变化趋势。
应用场景
- 应用性能监控:在 Web 应用程序中,StatsD 可以用于收集各种性能指标,如页面加载时间、数据库查询时间、接口响应时间等。通过分析这些指标,开发人员可以快速定位性能瓶颈,优化应用程序代码和架构。
- 业务指标统计:可以用来统计业务相关的数据,如用户注册量、登录次数、订单成交量等。这些数据对于了解业务发展趋势、评估营销策略效果具有重要意义。
- 系统资源监控:StatsD 还可以与服务器监控工具结合,收集系统资源使用情况的统计数据,如 CPU 使用率、内存使用率、磁盘 I/O 等。运维人员可以根据这些数据及时发现系统资源的异常消耗,提前进行资源调整和优化。
Jobs/exporters(作业 / 导出器)
- 作用
Jobs 主要用于告诉 Prometheus 服务器如何以及从哪里采集指标数据。它定义了一组目标(通常是 Exporter),并配置了采集这些目标数据的相关参数,是 Prometheus 实现对各种系统和应用进行监控的关键配置部分。
配置参数
job_name:每个 Job 都有一个唯一的名称,用于标识该作业,例如
web_server、database_monitor等,方便在 Prometheus 的配置和管理中进行区分和引用。scrape_interval:指定 Prometheus 从目标 Exporter 采集数据的时间间隔。默认是 15 秒,可以根据实际需求进行调整。如果监控的系统变化频繁,可能需要缩短采集间隔;如果系统相对稳定,可适当延长间隔以减少资源消耗。
scrape_timeout:设置采集数据的超时时间。当 Prometheus 向 Exporter 请求数据时,如果在指定的超时时间内没有收到响应,就会认为此次采集失败。默认是 10 秒,一般不需要修改,但在网络环境不稳定或 Exporter 处理数据较慢的情况下,可能需要适当延长超时时间。
targets:这是 Job 配置中最重要的部分,用于指定要采集数据的目标地址,通常是 Exporter 的地址和端口。可以是单个目标,如
['server1:9100'],也可以是多个目标的列表,如['server1:9100', 'server2:9100', 'server3:9100']。Prometheus 会按照配置的时间间隔依次向这些目标发送数据采集请求。labels:标签是 Prometheus 中用于对数据进行分类和标识的重要手段。在 Job 配置中,可以为采集到的数据添加一组标签,例如
env: 'production'、app: 'myapp'等。这些标签可以帮助用户在查询和分析数据时更方便地进行筛选、聚合和分组操作,以便更好地理解和监控系统的不同方面。
工作原理
Prometheus 服务器会按照 Job 配置中定义的
scrape_interval定期遍历每个 Job 中的targets列表,向每个目标 Exporter 发送 HTTP 请求,获取指标数据。Exporter 接收到请求后,会将自身收集到的指标数据以 Prometheus 支持的格式返回给 Prometheus 服务器。Prometheus 服务器接收到数据后,会根据 Job 配置中的labels以及 Exporter 返回数据中自带的标签信息,对数据进行标记和存储。这样,用户就可以通过 Prometheus 的查询界面或其他工具,根据标签来查询和分析采集到的指标数据,实现对系统的监控和故障排查。与其他组件的关系
Jobs 与 Exporter 紧密配合,Exporter 负责将各种系统和应用的指标数据转换为 Prometheus 能够识别的格式,而 Jobs 则负责告诉 Prometheus 如何去采集这些 Exporter 的数据。同时,Jobs 采集到的数据会存储在 Prometheus 的时间序列数据库中,供用户通过 **PromQL(Prometheus Query Language)**进行查询和分析。此外,Jobs 也可以与 Prometheus 的告警系统结合,根据采集到的数据设置告警规则,当某些指标超出阈值或满足特定条件时,及时向相关人员发送告警通知。
Node(节点)
代表运行 Prometheus server 的物理或虚拟节点,下方的 HDD/SSD 表示存储设备,用于存储 Prometheus 的数据。
在存储系统中,节点是一个具有独立处理能力和存储能力的单元。它可以是一台服务器、一个存储设备或一个特定的硬件模块,作为存储网络中的一个基本组成部分,负责存储和管理数据。多个节点可以通过网络连接在一起,形成一个分布式存储系统,共同提供大规模的数据存储和访问服务。每个节点都有自己的处理器、内存、存储设备和网络接口,能够独立地执行数据读写操作,并与其他节点进行通信和协作,以实现数据的冗余、容错和负载均衡等功能。
Prometheus alerting
工作原理
Prometheus 通过配置文件中的规则来定义警报条件。它会定期评估这些规则,检查监控指标是否符合设定的阈值或其他条件。当指标满足警报条件时,Prometheus 会将警报信息发送到配置好的 Alertmanager。
Alertmanager 负责接收来自 Prometheus 的警报信息,并对其进行处理,包括分组、抑制、去重等操作,然后根据配置将警报发送到指定的接收者,如邮件、即时通讯工具等。
警报规则配置
- 警报规则使用 Prometheus 的查询语言(PromQL)来定义。例如,可以定义当 CPU 使用率超过 80% 持续 5 分钟时触发警报:
1 | groups: |
- 在这个规则中,
expr字段是核心表达式,用于判断警报条件。for字段指定了持续时间,只有当条件满足该持续时间后才会触发警报。labels字段用于为警报添加标签,以便在 Alertmanager 中进行分类和过滤。annotations字段则提供了关于警报的详细描述信息,如摘要和具体描述。 expr中的[5m]:它是 PromQL 中rate函数的一部分,用于指定计算 CPU 使用率的时间窗口。在这里,它表示获取过去 5 分钟内node_cpu_seconds_total{mode="idle"}指标的变化率,即计算每 5 分钟的 CPU 空闲时间的平均变化速率,以此来间接得出 CPU 的使用率。for字段中的5m:它指定了警报触发的条件需要持续的时间。也就是说,只有当expr中定义的条件(CPU 使用率小于 0.2,即 CPU 使用率超过 80%)持续满足 5 分钟后,Prometheus 才会真正触发警报。
Alertmanager 配置
- 分组(Grouping):可以将相似的警报分组在一起,例如按照主机名或服务名进行分组,这样可以避免收到大量重复的警报信息。例如:
1 | route: |
group_by:这是一个列表,里面定义了用于分组的标签。在这个例子中,['instance'] 意味着会依据 instance 标签的值来对告警进行分组。例如,所有 instance 标签值相同的告警会被分到一组。
group_wait:表示在首次收到告警后,Alertmanager 会等待多长时间再发送分组后的通知。设置这个时间是为了让 Alertmanager 有时间收集更多相关的告警,然后一起发送。在这个例子中,等待时间是 30 秒。
group_interval:指的是在发送一个分组通知之后,下一次收集新告警并发送新分组通知之前的等待时间。这里设置为 5 分钟,也就是说,在发送一个分组通知后,接下来的 5 分钟内,新产生的告警会被收集起来,等到 5 分钟结束后,再把这些新告警作为一个新的分组通知发送出去。
repeat_interval:表示如果一个告警分组持续存在,那么每隔多长时间会再次发送通知。这里设置为 12 小时,意味着如果一个告警分组一直存在,每隔 12 小时会再次发送通知提醒接收者。
receiver:指定了分组通知的接收者。这里设置为 'email',表示使用名为 email 的接收者配置来发送通知。
- 抑制(Inhibition):可以配置当某些警报触发时,抑制其他相关警报的发送。例如,当服务器整体故障警报触发时,抑制该服务器上单个服务的故障警报。
1 | inhibit_rules: |
source_match:这是一个标签匹配规则,定义了触发抑制的告警需要满足的条件。在这个例子中,severity: 'critical' 表示只有当 severity 标签值为 critical 的告警触发时,才会触发抑制规则。
target_match:同样是一个标签匹配规则,定义了会被抑制的告警需要满足的条件。这里 severity: 'warning' 表示 severity 标签值为 warning 的告警会被抑制。
equal:这是一个列表,定义了在进行抑制判断时,需要比较的标签。在这个例子中,['instance'] 表示只有当触发抑制的告警和被抑制的告警的 instance 标签值相同时,才会进行抑制操作。也就是说,当 severity 为 critical 的告警触发时,会抑制 severity 为 warning 且 instance 标签值相同的告警。
1号数据库 慢查询 warning
2号数据库宕机 critical
- 去重(Deduplication):Alertmanager 会自动对相同的警报进行去重,只发送一次通知,避免重复通知给用户带来困扰。
警报接收方式
- Prometheus 支持多种警报接收方式,常见的有邮件、Slack、PagerDuty(一种事件管理和应急响应平台) 等。通过配置相应的接收器(Receiver),可以将警报信息发送到不同的平台。例如,配置邮件接收器:
1 | receivers: |
PromQL
(Prometheus Query Language,Prometheus 查询语言)
用于在 Prometheus web UI、Grafana 等工具中查询和分析存储在 Prometheus 中的指标数据。
基本语法
指标名称:直接使用指标名称可查询该指标的时间序列数据。例如,
http_requests_total表示 HTTP 请求的总数,它是一个反映系统中 HTTP 请求量的指标。标签选择器:用
{}来指定标签选择条件,用于过滤具有特定标签的时间序列。例如,1
http_requests_total{method="GET", status_code="200"}
表示仅选择 HTTP 请求方法为 GET 且状态码为 200 的请求总数的时间序列。标签选择器支持多种匹配模式,具体如下:
- 精确匹配(
=):node_cpu_seconds_total{mode="user"}会精确选择出 CPU 处于用户态的时间序列。 - 不精确匹配(
!=):node_cpu_seconds_total{mode!="system"}表示选择除了 CPU 处于系统态之外的其他时间序列。 - 正则表达式匹配(
=~和!~):node_labels{label_name=~"role.*"}会选择标签名为label_name且值以role开头的时间序列。
- 精确匹配(
数据类型
- 瞬时向量(Instant Vector):包含一组时间序列样本,每个样本都有一个唯一的时间戳和值,代表在某个特定时刻的指标数据。例如,
node_memory_MemAvailable_bytes可能返回当前时刻系统可用内存的字节数,它是一个瞬时向量,反映了当前这一时刻的内存可用情况。 - 范围向量(Range Vector):包含一段时间范围内的时间序列样本,通过指定时间范围来获取数据。例如,
http_requests_total{method="POST"}[10m]表示过去 10 分钟内 HTTP 请求方法为 POST 的请求总数的时间序列数据,它可以用于分析一段时间内 POST 请求的变化趋势。 - 标量(Scalar):一个单独的数字值,通常是通过对瞬时向量或范围向量进行聚合操作得到的结果。例如,
count(node_cpu_seconds_total)会返回 CPU 时间序列的数量,这是一个标量值,用于统计相关指标的数量。 - 字符串(String):主要用于在表达式中传递文本信息,例如标签的值或注释内容。例如,在查询中可以使用字符串来指定特定的标签值进行过滤,如
node_metadata{hostname="server01"},其中"server01"就是字符串。
操作符
- 算术操作符:包括+、-、*、/、%(取模)和^(幂运算)。这些操作符可对指标数据进行数学计算。例如:
node_memory_MemTotal_bytes - node_memory_MemFree_bytes用于计算系统已使用的内存字节数。http_requests_per_second * 60可以将每秒的 HTTP 请求数转换为每分钟的请求数。
- 比较操作符:有 ==、!=、>、<、>=和<=。比较操作符用于过滤满足特定条件的时间序列。例如:
node_cpu_utilization > 0.9可以选择出 CPU 使用率超过 90% 的节点,用于发现 CPU 负载较高的情况。http_response_time_ms <= 500表示选择 HTTP 响应时间小于等于 500 毫秒的时间序列,用于监控响应时间是否在正常范围内。
- 逻辑操作符:and、or、unless(除非)。逻辑操作符用于组合多个条件。例如:
(node_cpu_utilization > 0.8) and (node_memory_utilization > 0.7)表示选择 CPU 使用率超过 80% 且内存使用率超过 70% 的节点,用于找出系统资源整体使用较高的节点。(http_requests_total > 1000) or (http_error_rate > 0.05)表示选择 HTTP 请求总数超过 1000 或者错误率超过 5% 的时间序列,用于判断系统是否出现高请求量或高错误率的情况。
函数
聚合函数:PromQL 提供了丰富的聚合函数,用于对时间序列数据进行聚合计算。例如:
sum by (instance) (node_cpu_seconds_total{mode="idle"})会按照实例对 CPU 空闲时间进行求和,返回每个实例的 CPU 空闲时间总和,便于了解不同实例的 CPU 空闲情况。avg over time (http_requests_total[1h])计算过去 1 小时内 HTTP 请求总数的平均值,用于分析请求量的平均水平。max by (job) (node_memory_MemUsed_bytes)按照作业(job)标签找出每个作业中内存使用量的最大值,有助于发现内存使用的峰值情况。
数据转换函数
:可以对时间序列数据进行转换和处理。例如:
rate(node_cpu_seconds_total{mode="idle"}[5m])计算过去 5 分钟内 CPU 空闲时间的平均变化率,用于了解 CPU 空闲时间的变化趋势。irate(node_network_bytes_transmitted[1m])计算节点网络传输字节数的瞬时变化率,能及时反映网络流量的瞬间变化情况。delta(node_disk_io_time_seconds[10m])计算过去 10 分钟内磁盘 I/O 时间的差值,用于分析磁盘 I/O 的活动情况。
其他函数
:还有一些其他类型的函数。例如:
label_join(node_labels, "combined_label", " ", "label1", "label2")用于将label1和label2两个标签的值连接起来,形成一个新的标签combined_label,中间用空格分隔,方便对标签进行组合和处理。time()函数返回当前时间戳,可用于在查询中获取当前时间,以便与其他时间相关的指标进行比较或计算。
查询示例
- 查询当前所有节点的 CPU 使用率
1 | 1 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m]))) |
该查询先计算每个实例(instance)在过去 5 分钟内 CPU 空闲时间的平均变化率,然后用 1 减去这个值,得到的就是每个实例的 CPU 使用率。
- 查询内存使用率超过 80% 的节点
1 | (node_memory_MemUsed_bytes / node_memory_MemTotal_bytes) > 0.8 |
此查询通过计算内存已使用字节数与总内存字节数的比值,来判断每个节点的内存使用率是否超过 80%,如果超过则会被选中。
- 查询过去 1 小时内每秒请求数的变化趋势
1 | rate(http_requests_total[1h]) |
该查询使用 rate 函数计算过去 1 小时内 HTTP 请求总数的每秒变化率,从而展示出每秒请求数的变化趋势,帮助分析系统的负载情况。
- 查询特定服务的平均响应时间
1 | avg by (service) (rate(http_response_time_seconds_sum[5m]) / rate(http_response_time_seconds_count[5m])) |
这个查询通过计算过去 5 分钟内特定服务的响应时间总和与响应次数的比值,得到每个服务的平均响应时间,用于监控不同服务的性能。
- 查询集群中磁盘空间使用率最高的前 5 个节点
1 | topk(5, node_filesystem_used_percent{mountpoint="/"}) |
topk 函数用于找出指定指标中值最大的前 N 个元素,这里查询出根目录(mountpoint="/")磁盘空间使用率最高的前 5 个节点,方便及时发现磁盘空间紧张的节点。
Prometheus web UI
Prometheus 自带的 Web 界面,用户可以通过它使用 PromQL 查询指标数据,查看监控图表等。
Grafana
一个开源的数据可视化工具,连接 Prometheus 作为数据源,提供更丰富、美观的数据可视化界面和报表功能。
API clients(API 客户端)
通过 Prometheus 的 API 访问指标数据,进行数据导出等操作。
作用
- 数据查询:允许用户通过编程方式向 Prometheus 服务器发送查询请求,获取存储在其中的监控数据。例如,通过 API 客户端可以查询特定时间范围内的 CPU 使用率、内存使用量等指标数据,而无需在 Prometheus Web UI 中手动输入查询语句。
- 数据写入:某些 API 客户端还支持将数据写入 Prometheus 服务器。这对于一些自定义的监控数据收集器或者需要将外部数据导入到 Prometheus 进行分析的场景非常有用。比如,将应用程序内部的一些特定业务指标数据通过 API 客户端写入 Prometheus,以便进行统一的监控和分析。
- 配置管理:可以通过 API 客户端来管理 Prometheus 的配置,如添加或删除监控目标、更新警报规则等。这使得在自动化运维场景中,能够方便地通过脚本或程序来动态调整 Prometheus 的配置,而无需手动修改配置文件并重启服务。
常用的 API 客户端8888
- Prometheus 官方 Python 客户端:官方提供的 Python 库,方便 Python 开发者与 Prometheus API 进行交互。它提供了简洁的接口,用于构建查询语句、发送请求以及处理响应数据。以下是一个简单的示例代码,用于查询 Prometheus 中 CPU 使用率的指标数据:
1 | from prometheus_api_client import PrometheusConnect |
- Prometheus 官方 Go 客户端:对于 Go 语言开发者,官方提供了相应的客户端库。它与 Go 的标准库和生态系统集成良好,能够高效地与 Prometheus API 进行通信。以下是一个基本的 Go 语言示例,用于查询 Prometheus 中的内存使用指标:
1 | package main |
- Prometheus 官方 Java 客户端:用于 Java 项目中与 Prometheus API 进行交互。它提供了 Java 风格的接口,便于在 Java 应用程序中集成 Prometheus 的查询和数据写入功能。以下是一个简单的 Java 示例,用于查询 Prometheus 中的网络流量指标:
1 | import io.prometheus.client.CollectorRegistry; |
优势
- 自动化与集成:便于与其他系统和工具集成,实现监控数据的自动化处理和分析。例如,可以将 Prometheus API 客户端集成到持续集成 / 持续部署(CI/CD)流程中,在每次部署后自动查询相关指标数据,以验证系统的性能和稳定性。
- 定制化开发:允许开发人员根据具体的业务需求,定制特定的监控和分析功能。通过 API 客户端获取原始数据后,可以进行自定义的计算、过滤和可视化处理,满足不同用户对于监控数据的个性化需求。
- 远程操作:即使不在 Prometheus 服务器所在的本地环境,也可以通过网络远程连接到 Prometheus 服务器的 API,进行数据查询和管理操作。这对于分布式系统的监控和管理非常方便,运维人员可以在任何有网络连接的地方通过 API 客户端对 Prometheus 进行操作。
线条部分
- push metrics at exit(退出时推送指标):表示短期作业在结束运行时,将自身的指标数据推送到 Pushgateway。
- pull metrics(拉取指标):Prometheus server 从 Pushgateway 和 Jobs/exporters 拉取指标数据。
- discover targets(发现目标):Service discovery 组件通过 Kubernetes 或 file_sd 机制发现 Prometheus 的监控目标。
- push alerts(推送告警):Prometheus alerting 将检测到的告警信息推送给 Alertmanager。
- notify(通知):Alertmanager 将处理后的告警信息通过 PagerDuty、Email 等方式通知相关人员。
- 其他线条:表示数据在各个组件之间的流动和交互,如 PromQL 用于查询 Prometheus server 中的数据,供 Prometheus web UI、Grafana 和 API clients 使用 。
Prometheus的数据模型
Prometheus 基本上将所有数据存储为时间序列:属于同一指标和相同一组标记维度的时间戳值流。除了存储的时间序列外,Prometheus 还可能根据查询结果生成临时派生时间序列。
指标名称和标签
每个时间序列都通过其指标名称和可选的键值对(称为标签)来唯一标识。
指标名称:
- 指定被测系统的一般特征(例如 - 收到的 HTTP 请求总数)。
http_requests_total - 指标名称可以包含 ASCII 字母、数字、下划线和冒号。它必须与 regex(正则表达式) 匹配。
[a-zA-Z_:][a-zA-Z0-9_:]*
注意:冒号是为用户定义的录制规则保留的。导出器或直接检测不应使用它们。
指标标签:
- 启用 Prometheus 的维度数据模型,以识别同一指标名称的任何给定标签组合。它标识该指标的特定维度实例(例如:使用该方法的所有 HTTP 请求到处理程序)。查询语言允许基于这些维度进行筛选和聚合。
POST``/api/tracks - 更改任何标签的值(包括添加或删除标签)都将创建新的时间序列。
- 标签可以包含 ASCII 字母、数字以及下划线。它们必须与 regex 匹配。
[a-zA-Z_][a-zA-Z0-9_]* - 以 (两个 “_”) 开头的标签名称保留供内部使用。
__ - 标签值可以包含任何 Unicode 字符。
- 标签值为空的标签被视为等同于不存在的标签。
例如,假设你有一个指标名称叫做 http_requests,用来记录HTTP请求的数量。你可以添加一些标签来进一步描述这些请求,比如:
method="GET":表示这是一个GET请求。handler="/api/users":表示请求是针对/api/users这个处理程序的。status="200":表示请求成功返回了状态码200。
因此,一个带有标签的时间序列可能看起来像这样:
1 | http_requests{method="GET", handler="/api/users", status="200"} 50 |
在这个例子中,method、handler 和 status 就是标签,它们为 http_requests 指标提供了额外的上下文信息。这些标签可以帮助你在查询和分析数据时更精确地定位和分类时间序列
例如,如果你在监控一个网站的访问量,一个样品可能如下所示:
- 值(float64):
120.5(例如,表示在某个特定时刻的每秒访问量) - 时间戳(毫秒精度):
2024-03-24T13:52:37.456Z(表示这个访问量数据是在2024年3月24日13时52分37秒456毫秒时记录的)
在Prometheus中,这样的样品可能会被存储和表示为:
1 | http_requests_total{method="GET", handler="/api/users"} 120.5 1679600377456 |
Prometheus的指标类型(4种)
Prometheus 客户端库提供了四种核心指标类型。这些类型目前仅在客户端库中有所区分(以支持针对特定类型使用而定制的API),以及在网络协议中有所区分。Prometheus 服务器尚未利用这些类型信息,而是将所有数据扁平化为无类型的时序数据。
Counter
计数器的定义:
- 计数器是一种累积式指标(cumulative metric),意味着它的值只能增加或在重启时重置为零。
- 计数器的值是单调递增的,即它只能上升,不能下降。
计数器的用途:
- 计数器可以用来表示请求的数量、完成的任务数量或发生的错误数量等。
- 这些场景下的数值都是随着时间的推移而增加的,或者在服务重启时重置。
计数器的使用方法:
- 不应该使用计数器来表示可能减少的值。例如,不应该用计数器来表示当前正在运行的进程数量。
- 对于可能减少的值,应该使用另一种类型的指标,如仪表(gauge)。
例子
1 | from prometheus_client import Counter |
Gauge
仪表的定义:
- 仪表是一种可以任意上升或下降的单个数值指标。
- 与计数器(Counter)不同,仪表的值没有单调性要求,即它的值可以增加也可以减少。
仪表的用途:
- 仪表通常用于表示测量值,如温度、当前内存使用量等。
- 也适用于那些可以上升和下降的“计数”,例如并发请求的数量。
仪表的应用场景:
- 当你需要监控的数值会随着时间变化而增减时,使用仪表是合适的。
- 例如,如果你想要监控当前系统中正在运行的进程数量,这个数量可能会随着进程的启动和结束而变化,这时就应该使用仪表。
- 另一个例子是监控队列中的任务数量,这个数量也会随着任务的添加和完成而变化。
Histogram
直方图的定义和用途:
- 直方图用于采样观察值(例如请求持续时间或响应大小),并将这些观察值计数在可配置的桶(buckets)中。
- 它还提供了所有观察值的总和。
直方图的暴露时间序列:
- 在Prometheus中,直方图在一次抓取(scrape)过程中会暴露多个时间序列。这些时间序列基于基本指标名称(basename)。
直方图暴露的具体时间序列:
- 观察桶的累积计数器:这些计数器表示每个桶中观察值的数量,暴露为
<basename>_bucket{le="<upper inclusive bound>"}。这里的le表示“小于或等于”(less than or equal to),<upper inclusive bound>是桶的上界。 - 所有观察值的总和:暴露为
<basename>_sum。 - 已观察事件的计数:暴露为
<basename>_count。这个计数与<basename>_bucket{le="+Inf"}相同,表示所有观察值的总数。
计算分位数:
- 使用
histogram_quantile()函数可以从直方图中计算分位数,甚至可以计算直方图聚合的分位数。 - 直方图也适合计算 Apdex 分数(一种衡量用户体验的指标)。
直方图的累积性质:
- 当操作桶时,需要记住直方图是累积的。这意味着每个桶包括它自身以及所有更小桶的观察值。
直方图与摘要(Summaries)的区别:
- 直方图是暴露桶观察计数器给服务端,计算分位数是交给服务端来计算。摘要直接暴露分位数,分位数的计算由客户端进行计算 ,缓解服务端压力。
举例
下面结合一个具体的请求响应时间监控的例子,来详细讲解直方图的相关概念:
假设我们正在监控一个 Web 应用的请求响应时间,使用直方图来统计这些响应时间的分布情况。我们将基础指标名称设定为 http_request_duration_seconds。
样本观测与桶计数
我们预先配置了以下几个桶来统计请求响应时间:[0.1, 0.2, 0.5, 1.0, 2.0],单位是秒。这意味着我们把响应时间划分为以下几个区间:
- 小于等于 0.1 秒
- 大于 0.1 秒且小于等于 0.2 秒
- 大于 0.2 秒且小于等于 0.5 秒
- 大于 0.5 秒且小于等于 1.0 秒
- 大于 1.0 秒且小于等于 2.0 秒
在一段时间内,Web 应用处理了 100 个请求,响应时间各不相同。直方图会对每个请求的响应时间进行采样,并将其归入相应的桶中。假设统计结果如下:
- 响应时间小于等于 0.1 秒的请求有 20 个
- 响应时间大于 0.1 秒且小于等于 0.2 秒的请求有 30 个
- 响应时间大于 0.2 秒且小于等于 0.5 秒的请求有 25 个
- 响应时间大于 0.5 秒且小于等于 1.0 秒的请求有 15 个
- 响应时间大于 1.0 秒且小于等于 2.0 秒的请求有 10 个
直方图暴露的时间序列
观测桶的累积计数器 ,由于直方图是累积的,每个桶的计数包含了小于或等于该桶上限的所有观测值的数量。所以,我们会得到以下时间序列:
http_request_duration_seconds_bucket{le="0.1"}= 20 ,表示响应时间小于等于 0.1 秒的请求数量为 20 个。http_request_duration_seconds_bucket{le="0.2"}= 20 + 30 = 50 ,表示响应时间小于等于 0.2 秒的请求数量为 50 个(包含了小于等于 0.1 秒的 20 个)。- http_request_duration_seconds_bucket{le=”0.1”}[5m]
http_request_duration_seconds_bucket{le="0.5"}= 20 + 30 + 25 = 75 ,表示响应时间小于等于 0.5 秒的请求数量为 75 个。http_request_duration_seconds_bucket{le="1.0"}= 20 + 30 + 25 + 15 = 90 ,表示响应时间小于等于 1.0 秒的请求数量为 90 个。http_request_duration_seconds_bucket{le="2.0"}= 20 + 30 + 25 + 15 + 10 = 100 ,表示响应时间小于等于 2.0 秒的请求数量为 100 个。http_request_duration_seconds_bucket{le="+Inf"}= 100 ,因为+Inf表示正无穷大,所以这个桶包含了所有的请求。
所有观测值的总和
假设这 100 个请求的响应时间总和是 35 秒,那么会暴露时间序列 http_request_duration_seconds_sum = 35 。这个值可以用来计算平均响应时间等统计信息。
- 观测事件的计数
时间序列 http_request_duration_seconds_count = 100 ,这与 http_request_duration_seconds_bucket{le="+Inf"} 的值是相同的,都表示总的请求数量。
直方图的常见用途
- 分位数计算
使用 histogram_quantile() 函数可以计算分位数。例如,我们想计算响应时间的 90 分位数(90 分位数就是将数据从小到大排序后,使得 90% 的数据小于等于该值,10% 的数据大于该值),可以使用以下 PromQL 查询:
1 | histogram_quantile(0.9, http_request_duration_seconds_bucket) |
这个查询会根据直方图的数据计算出有 90% 的请求响应时间小于该值的具体时间,帮助我们了解系统在大多数情况下的性能表现。
Apdex 分数计算 假设我们定义 Apdex 的满意时间阈值为 0.2 秒,可容忍时间阈值为 1.0 秒。根据直方图的数据,我们可以计算出:
满意的请求数量(响应时间小于等于 0.2 秒):50 个
可容忍的请求数量(响应时间大于 0.2 秒且小于等于 1.0 秒):90 - 50 = 40 个
不满意的请求数量(响应时间大于 1.0 秒):100 - 90 = 10 个
根据 Apdex 分数的计算公式:Apdex = (满意请求数 + 可容忍请求数 / 2) / 总请求数,可以计算出该应用的 Apdex 分数为 (50 + 40 / 2) / 100 = 0.7 ,这个分数可以直观地反映出用户对应用性能的满意度。
Summary (1888滑动时间默认值,【】)
摘要的定义和用途
- 摘要用于采样观察值(例如请求持续时间或响应大小)。
- 它提供了观察值的总数和所有观察值的总和。
- 与直方图不同的是,摘要计算的是可配置的分位数(quantiles),这些分位数是在滑动时间窗口上计算的。
摘要暴露的时间序列
在Prometheus中,一个摘要指标在一次抓取(scrape)过程中会暴露多个时间序列。这些时间序列基于基本指标名称(basename):
- 流式φ-分位数:φ-分位数(0 ≤ φ ≤ 1)表示在滑动时间窗口内观察到的事件的分位数,暴露为
<basename>{quantile="<φ>"}。这里的φ是一个介于0和1之间的数值,表示分位数。例如,<basename>{quantile="0.5"}表示中位数(50%的分位数)。 - 所有观察值的总和:暴露为
<basename>_sum。这表示在滑动时间窗口内所有观察值的总和。 - 已观察事件的计数:暴露为
<basename>_count。这表示在滑动时间窗口内观察到的事件总数。
φ-分位数
φ-分位数是一种统计量,用于描述数据分布的特定百分位。例如,φ=0.5表示中位数,φ=0.9表示90%的数据点都低于这个值。在摘要中,你可以配置不同的φ值来计算不同的分位数,这对于了解数据的分布情况非常有用。
摘要与直方图的区别
- 直方图:提供一系列预定义的桶,用于计算落入每个桶的观测值数量。直方图是累积的,每个桶包括它自身以及所有更小桶的观测值。
- 摘要:计算滑动时间窗口内的分位数,不提供桶的计数。摘要不是累积的,它只计算在滑动窗口内的观测值。
使用摘要
摘要适用于需要了解数据分布的实时统计信息的场景,如计算请求持续时间的中位数或90%分位数。这些信息可以帮助你了解大多数请求的性能,以及可能存在的性能瓶颈。
指标类型为什么只在客户端分类
客户端和服务端的区别
- 客户端:在 Prometheus 体系中,客户端通常是指被监控的应用程序或服务所在的一端。它负责收集自身的各种运行指标数据,如应用程序的请求响应时间、内存使用量、CPU 使用率等,并按照 Prometheus 规定的格式和协议将这些数据提供给服务端。客户端需要使用 Prometheus 的客户端库来实现指标的定义、收集和暴露等功能。不同的编程语言都有相应的 Prometheus 客户端库,如 Python 的
prometheus_client库。 - 服务端:Prometheus 服务端是专门用于存储、管理和查询指标数据的组件。它会定期从各个客户端(也称为目标)抓取指标数据,并将这些数据存储在本地的时间序列数据库中。服务端提供了强大的查询语言(PromQL),用于对存储的指标数据进行分析、聚合和可视化展示等操作。
在 Prometheus 监控体系中,客户端收集数据的方式既可以借助 Exporter,也可以自己编写代码。
使用 Exporter 收集数据
- Exporter 的作用:Exporter 是一种专门为 Prometheus 设计的代理程序,其主要功能是将各种不同类型系统或服务的指标数据转换为 Prometheus 能够识别的格式。比如,Node Exporter 可以收集服务器节点的 CPU、内存、磁盘等系统指标;MySQL Exporter 可以收集 MySQL 数据库的查询性能、连接数等指标。
- 适用场景:当你要监控的目标是常见的系统或服务,且已有对应的 Exporter 时,使用 Exporter 是非常便捷的选择。你无需了解这些系统或服务内部复杂的指标收集逻辑,只需要安装并配置好相应的 Exporter,它就会自动收集和暴露指标数据。例如,要监控 Linux 服务器的性能,安装并启动 Node Exporter 后,Prometheus 就能从其暴露的
/metrics端点获取服务器的各项指标。
自己编写代码收集数据
- 代码收集的必要性:在某些情况下,你无法使用现有的 Exporter,或者需要对应用程序的特定业务指标进行监控,这时就需要自己编写代码来收集数据。比如,你想监控其他数据库例如postgreSQL,没有现成的 Exporter 可以使用。
- 代码实现方式:借助 Prometheus 提供的客户端库,你可以轻松地在代码中定义和收集指标。不同的编程语言都有对应的客户端库,例如 Python 的
prometheus_client、Java 的prometheus_client_java等。在代码中,你可以根据业务需求选择合适的指标类型,如使用 Counter 记录请求次数,使用 Summary 统计请求响应时间的分布等。以下是一个 Python 示例: - 2888:运行
1 | import time |
在这个示例中,我们使用三个指标来记录。然后启动一个 HTTP 服务器,将指标暴露在 8000 端口的 /metrics 端点,供 Prometheus 抓取。
客户端配置好后如何配置服务器端呢?
当你使用客户端代码将 PostgreSQL 指标暴露在本地的 8000 端口后,需要对 Prometheus 服务端进行配置,使其能够定期从该端点抓取指标数据。以下是具体的配置步骤:
1. 编辑 Prometheus 配置文件
Prometheus 的配置文件通常是 prometheus.yml,你需要在这个文件中添加一个新的 scrape_config 部分,以指定要监控的目标和相关参数。以下是一个示例配置:
1 | # 全局配置 |
配置解释
global部分:scrape_interval:定义了 Prometheus 全局的抓取间隔,这里设置为每 15 秒抓取一次指标。evaluation_interval:定义了 Prometheus 评估告警规则的间隔,同样设置为每 15 秒评估一次。
scrape_configs部分:job_name:为每个抓取任务指定一个名称,这里postgresql_metrics表示用于监控 PostgreSQL 指标的任务。static_configs:指定要监控的目标列表,targets中的localhost:8000是客户端代码中启动的 HTTP 服务器的地址和端口,即指标暴露的端点。
2. 重启 Prometheus 服务
在修改完 prometheus.yml 配置文件后,需要重启 Prometheus 服务,使其加载新的配置。具体的重启命令取决于你的操作系统和 Prometheus 的安装方式。
Linux 系统
如果你使用 systemd 来管理 Prometheus 服务,可以使用以下命令重启:
1 | sudo systemctl restart prometheus |
Docker 环境
如果你使用 Docker 运行 Prometheus,可以使用以下命令重新启动容器:
1 | docker restart <prometheus_container_id> |
其中 <prometheus_container_id> 是 Prometheus 容器的 ID。
3. 验证配置是否生效
- 查看 Prometheus 状态:打开浏览器,访问
http://localhost:9090(如果 Prometheus 运行在本地的 9090 端口),进入 Prometheus 的 Web 界面。 - 检查目标状态:在 Prometheus 界面中,点击左侧菜单中的 “Status” -> “Targets”,查看
postgresql_metrics任务的状态。如果状态显示为 “UP”,则表示 Prometheus 已经成功连接到客户端的指标暴露端点,并开始抓取指标数据。 - 查询指标:在 Prometheus 界面的查询框中输入相关的指标名称,如
postgresql_connections、postgresql_active_transactions或postgresql_database_size_bytes,然后点击 “Execute” 按钮进行查询。如果能够看到相应的指标数据,则说明配置已经生效。
4. 可视化指标(可选)
你可以使用 Grafana 等可视化工具来展示 Prometheus 中的指标数据。具体步骤如下:
- 安装和配置 Grafana:根据你的操作系统和需求,安装 Grafana 并启动服务。
- 添加 Prometheus 数据源:在 Grafana 界面中,点击左侧菜单中的 “Configuration” -> “Data Sources”,然后点击 “Add data source”,选择 “Prometheus”,并配置 Prometheus 的地址(通常是
http://localhost:9090)。 - 创建仪表盘:在 Grafana 中创建一个新的仪表盘,添加相应的图表,并使用 PromQL 查询语句从 Prometheus 中获取指标数据进行展示。
通过以上步骤,你就可以完成 Prometheus 服务端的配置,使其能够接收和监控客户端暴露的 PostgreSQL 指标数据。
“安装指标类型” 的过程
内部存储时不区分指标类型
Prometheus 采用时间序列数据库来存储数据,其核心存储的是样本(Sample),样本由指标名、标签集合以及对应的时间戳和数值构成。==在存储层面,不管是 Counter、Gauge、Histogram 还是 Summary 类型的指标,都以相同的底层格式存储,也就是只关注指标名、标签、时间戳和数值,不特别区分其指标类型。这样做的好处是简化了存储逻辑,提升了存储效率。
指标类型信息的记录
虽然存储时不区分类型,但在客户端(如应用程序中的 Exporter)向 Prometheus 服务器推送数据时,会附带指标类型的元数据。例如,Python 的 prometheus_client 库在定义指标时,就会明确指定指标类型:
1 | from prometheus_client import start_http_server, Counter |
在这个例子中,REQUEST_COUNTER 被明确定义为 Counter 类型。当客户端向 Prometheus 服务器发送数据时,会把这个类型信息一同发送过去。
元数据的存储与关联
Prometheus 服务器接收到客户端发送的数据后,会将指标类型等元数据存储在内部的元数据结构中,并且把这些元数据和对应的时间序列关联起来。也就是说,虽然存储样本数据时不区分类型,但服务器会另外记录每个指标的类型信息,并建立起与时间序列的对应关系。
查询和展示时利用类型信息
- 查询处理:当用户发起查询请求时,Prometheus 会先从元数据中获取该指标的类型信息。例如,当使用
rate()函数查询一个指标时,Prometheus 会检查该指标的类型,如果是Counter类型,就按照Counter的特性(只增不减)来计算速率;如果是其他类型,就可能给出错误提示,因为rate()函数主要用于Counter类型。 - 展示处理:在将查询结果展示给用户时,可视化工具(如 Grafana)会从 Prometheus 获取指标的类型信息。根据不同的类型,采用不同的可视化方式。例如,对于
Counter类型,通常展示其增长趋势;对于Gauge类型,展示当前值和变化趋势等。
过程类比
可以把指标类型信息看作是一种特殊的 “标签”,它的 “安装” 过程如下:
- 客户端定义:在客户端代码里,开发者定义指标时就明确指定了指标类型,这就好比给指标贴上了类型 “标签”。
- 数据传输:客户端向 Prometheus 服务器发送数据时,会把这个类型 “标签” 一同发送过去。
- 服务器关联:Prometheus 服务器接收到数据后,将类型 “标签” 存储在元数据中,并和对应的时间序列关联起来,就像把标签贴到了具体的物品上。
- 查询展示使用:在查询和展示时,Prometheus 或可视化工具会读取这个类型 “标签”,根据标签的内容来正确处理和展示数据。
Prometheus部署
作者:王文杰
日期:2024年3月25日
环境
虚拟机Ubuntu20.04 内存4GB CPU2核 硬盘40GB
安装部署prometheus
解压prometheus
1 | tar xvfz prometheus-*.tar.gz |
配置prometheus.yml文档(样例)
1 | global: |
运行prometheus
1 | # Start Prometheus. |
创建systemd服务
切换root用户
1 | sudo -i |
将移动解压后的文件名到/opt/,并改名为prometheus
1 | mv prometheus-2.53.4.linux-amd64 /opt/prometheus |
创建一个专门的prometheus用户
1 | useradd -M -s /user/sbin/nologin prometheus |
赋予权限
1 | chown prometheus:prometheus -R /opt/prometheus |
Prometheus创建一个systemd服务单元文件,你需要创建一个名为 prometheus.service 的文件,并将以下内容添加到该文件中。这个文件通常位于 /etc/systemd/system/ 目录下
1 | vim /etc/systemd/system/prometheus.service |
1 | [Unit] |
运行prometheus
1 | systemctl start prometheus |
外部打开链接即可查看
查看监控指标
http://192.168.8.130:9090/metrics
systemctl 命令
停止服务
1 | sudo systemctl stop <服务名> |
启动服务
1 | sudo systemctl start <服务名> |
查看服务状态
1 | sudo systemctl status <服务名> |
显示服务的详细信息,包括它是否正在运行、启动日志等。
重启服务
1 | sudo systemctl restart <服务名> |
查看服务是否设置为开机启动
1 | sudo systemctl is-enabled <服务名> |
如果服务已启用,命令将输出 enabled;如果未启用,则输出 disabled。
设置服务开机启动
1 | sudo systemctl enable <服务名> |
禁用服务开机启动
1 | sudo systemctl disable <服务名> |
查看所有已加载的服务单元
1 | systemctl list-units --type=service |
查看所有已启用的服务
1 | systemctl list-unit-files --type=service |
查看服务的日志
1 | journalctl -u <服务名> |
这将显示服务的日志信息,包括启动和运行时的日志。
监控Linux服务器
服务器上下载Node_exporter
1 | tar -xzvf node_exporter-*.*.tar.gz |
prometheus.yml文件增加信息
1 | - job_name: 'node' |
配置查询规则
1 | avg by (job, instance, mode) (rate(node_cpu_seconds_total[5m])) |
创建prometheus.rules.yml文件,写入如下内容:
1 | groups: |
prometheus.yml文件规则信息
1 | rule_files: |
这样输入job_instance_mode:node_cpu_seconds:avg_rate5m 就能执行代码avg by (job, instance, mode) (rate(node_cpu_seconds_total[5m]))
配置
要指定要加载的配置文件,请使用 flag。--config.file
全局配置
1 | global: |
evaluation
在 Prometheus 中,“评估规则的频率” 指的是 Prometheus 对规则文件里定义的规则(包括记录规则和告警规则)进行计算和评估的时间间隔。这一频率由 evaluation_interval 参数设定,默认值为 1 分钟。下面分别为你介绍记录规则和告警规则的评估情况:
记录规则评估
记录规则可以把复杂的 PromQL 查询表达式预先计算并保存为新的时间序列数据,以此提升后续查询的效率。评估规则的频率决定了 Prometheus 多长时间重新计算一次这些规则,并更新对应的记录指标。
示例
假设你定义了一个记录规则,用于计算每 5 分钟内 HTTP 请求的平均响应时间:
1 | groups: |
若 evaluation_interval 设置为 1 分钟,那么 Prometheus 会每分钟对这个规则进行一次评估,重新计算 job_instance:http_request_duration_seconds:avg_rate5m 指标的值,并更新对应的时间序列数据。
告警规则评估
告警规则用于定义触发告警的条件。评估规则的频率决定了 Prometheus 多久检查一次这些条件是否满足,进而判断是否需要触发告警。
示例
假设你定义了一个告警规则,当 CPU 使用率超过 80% 时触发告警:
1 | groups: |
若 evaluation_interval 设置为 1 分钟,Prometheus 会每分钟检查一次 expr 表达式的计算结果是否满足条件(即 CPU 使用率是否超过 80%)。若连续 5 分钟(由 for 字段指定)都满足条件,就会触发告警。
频率设置的影响
- 频率过高:会让 Prometheus 频繁进行规则计算,增加 CPU 和内存的使用量,可能影响系统性能。
- 频率过低:可能导致告警延迟触发,无法及时发现系统问题;或者记录指标的数据更新不及时,影响监控和分析的实时性。
记录规则和告警规则融合
1 | groups: |
external_labels
1 | global: |
在 global 配置块中,定义了两个外部标签:
monitor: 'production_monitor':表示这个监控系统是用于生产环境监控的,可用于区分不同的监控实例,比如开发环境、测试环境等。environment: 'prod':明确指出监控的环境是生产环境。
与 Alertmanager 通信时标签的作用
当 Prometheus 触发一个告警并将其发送给 Alertmanager 时,所有的告警信息都会带上这些外部标签。假设我们有一个关于 CPU 使用率过高的告警规则:
1 | groups: |
当这个告警触发时,发送给 Alertmanager 的告警信息除了本身的 severity: 'critical' 标签外,还会带上 monitor: 'production_monitor' 和 environment: 'prod' 标签。Alertmanager 可以根据这些标签进行告警的路由和处理,例如:
1 | route: |
在这个 Alertmanager 配置中,根据 environment 和 severity 标签,将生产环境中的严重告警路由到 prod-critical-receiver 进行处理。
与远程存储通信时标签的作用
当 Prometheus 将时间序列数据写入远程存储时,这些外部标签也会被添加到每个时间序列中。例如,对于 http_requests_total 这个指标,原本的数据可能是:
1 | http_requests_total{job="webserver", instance="server1.example.com"} 100 |
添加外部标签后,存储到远程存储的数据会变成:
1 | http_requests_total{job="webserver", instance="server1.example.com", monitor="production_monitor", environment="prod"} 100 |
这样,在从远程存储查询数据时,可以根据这些标签进行筛选,例如只查询生产环境下的监控数据:
1 | http_requests_total{environment="prod"} |
通过添加外部标签,可以更好地对与外部系统通信的时间序列和警报进行管理和区分,提高监控和告警系统的灵活性和可维护性。
避免携带标签错误
加入外部标签是生产环境,此时其他环境的实例发生了告警,那么由于外部标签是全局的,那么是否会携带标签错误呢?
如果在 Prometheus 中设置了全局的外部标签为生产环境,而其他环境**(如开发环境、测试环境)**的实例发生了告警,确实可能会存在标签携带不准确的情况。 因为全局外部标签会被添加到所有与外部系统通信的时间序列和警报中,无论这些实例实际处于哪个环境。这可能导致在告警信息或时间序列数据中,环境相关的标签与实际情况不符,给监控和故障排查带来一定的干扰。
为了避免这种情况,可以考虑以下几种解决方法:
- 使用环境特定的配置文件:为不同的环境(生产、开发、测试等)创建独立的 Prometheus 配置文件,在每个配置文件中设置相应环境的外部标签。这样,每个环境的 Prometheus 实例都会使用正确的标签来标识告警和时间序列数据。
- 动态设置外部标签:通过 Prometheus 的 API 或配置管理工具,根据实际的运行环境动态地设置外部标签。例如,在启动 Prometheus 时,根据环境变量来设置不同的外部标签。
- 在告警规则中添加环境判断:在告警规则中添加对环境相关标签或指标的判断,确保只有在符合特定环境条件时才触发告警,并在告警信息中准确地反映实际环境。例如:
1 | groups: |
这个告警规则只会在非生产环境(通过environment != 'prod'判断)中,当 CPU 使用率超过 80% 时触发告警,并在告警信息中明确指出是非生产环境。
通过以上方法,可以更准确地处理不同环境下的告警和监控数据,避免因全局外部标签导致的标签错误问题。
query_log_file
1 | global: |
上述配置指定将 PromQL 查询日志记录到 /var/log/prometheus/query.log 文件中。
scrape_failure_log_file 配置同上。
scrape_config_files
在 Prometheus 中,抓取配置用于定义 Prometheus 要监控的目标以及如何从这些目标抓取指标数据。而 “指定包含抓取配置的文件的通配符列表,Prometheus 会读取所有匹配的文件并将配置追加到抓取配置列表中” 这一机制,主要是为了增强配置管理的灵活性和可维护性。
通配符列表
通配符是一种用于匹配文件名的特殊字符。在文件路径中使用通配符,可以方便地指定一组文件名。常见的通配符有 * 和 ? ,其中 * 可以匹配任意数量(包括零个)的任意字符,? 可以匹配单个任意字符。例如,*.yml 可以匹配所有以 .yml 结尾的文件,config-?.yml 可以匹配像 config-1.yml、config-a.yml 这类文件名。
配置追加到抓取配置列表
Prometheus 的主配置文件(通常是 prometheus.yml)中有一个 scrape_config_files 字段,你可以在这个字段中指定包含抓取配置的文件的通配符列表。Prometheus 启动时,会读取主配置文件,然后根据 scrape_config_files 中指定的通配符,去查找所有匹配的文件,并将这些文件中的抓取配置读取出来,追加到主配置文件的抓取配置列表中。
示例说明
假设你的 Prometheus 主配置文件 prometheus.yml 内容如下:
1 | # 主配置文件 prometheus.yml |
这里 scrape-configs/*.yml 就是一个通配符列表,表示 scrape-configs 目录下所有以 .yml 结尾的文件。
假设 scrape-configs 目录下有两个文件:
scrape-configs/app1.yml
1 | # scrape-configs/app1.yml |
scrape-configs/app2.yml
1 | # scrape-configs/app2.yml |
当 Prometheus 启动时,会读取 prometheus.yml,然后根据 scrape-config_files 中的通配符 scrape-configs/*.yml,找到 scrape-configs/app1.yml 和 scrape-configs/app2.yml 这两个文件,并将它们中的抓取配置追加到主配置文件的抓取配置列表中。最终,Prometheus 会将 app1.example.com:9090 和 app2.example.com:9091 作为监控目标进行指标抓取。
alerting
在 Prometheus 的配置文件中,alerting 部分用于配置警报相关的功能,以下是 alert_relabel_configs 和 alertmanagers 的详细解释及配置示例:
alert_relabel_configs
- 作用:用于对警报进行重新标记配置。可以在将警报发送到 Alertmanager 之前,根据指定的规则对警报的标签进行修改、添加或删除操作,以便更好地对警报进行分类、过滤和路由。
- 配置参数:
source_labels:指定要提取值的源标签列表。separator:多个源标签值之间的分隔符,默认为;。target_label:目标标签,即要将处理后的值设置到的标签。regex:用于匹配源标签值的正则表达式,默认为(.*)。replacement:匹配正则表达式后用于替换的值,默认为$1。action:执行的操作,如replace(替换)、keep(保留符合条件的)、drop(丢弃符合条件的)等。
- 配置示例
1 | alerting: |
上述示例中,对于 alertname 标签值为 HighCPUUsage 的警报,会添加一个 severity 标签,值为 critical。
alertmanagers
- 作用:用于指定 Alertmanager 的地址等信息,Prometheus 通过该配置将警报发送到 Alertmanager 进行后续的处理,如通知发送、警报分组等。
- 配置参数:
static_configs:包含静态配置的列表,用于指定 Alertmanager 的地址。name:Alertmanager 实例的名称,可选。
- 配置示例
1 | alerting: |
上述示例中,指定了一个 Alertmanager 实例的地址为 alertmanager.example.com:9093,Prometheus 会将警报发送到这个地址。
配置多个alertmanagers
1 | alerting: |
storage
tsdb 配置
- 含义:
tsdb是 Prometheus 用于存储时间序列数据的组件。这部分配置主要用于调整时间序列数据库的行为和性能,包括数据的存储路径、保留时间、块大小等参数。通过合理配置tsdb,可以优化 Prometheus 对时间序列数据的存储和查询效率,确保系统能够稳定地处理大量的监控数据。 - 示例配置:
1 | storage: |
- 配置解释:上述配置中,
path指定了 TSDB 数据文件的存储位置;retention.time设置了数据保留的时长,超过这个时间的数据将被自动删除;block.resolution定义了数据块的时间分辨率,即每个数据块包含的数据点的时间间隔。
exemplars 配置
- 含义:Exemplars 是与特定时间序列数据点相关联的示例数据,它可以为时间序列数据提供更详细的上下文信息,例如,在分布式系统中,exemplars 可以包含与某个指标数据点相关的请求 ID、跟踪 ID 等信息,帮助用户快速定位问题。
exemplars配置用于控制 Prometheus 如何处理和存储这些示例数据。 - 示例配置:
1 | storage: |
- 配置解释:这里配置了示例数据的存储类型为本地存储(
local),并指定了存储路径为/data/prometheus/exemplars。同时,设置了示例数据的保留时间为 7 天,即超过 7 天的示例数据将被删除。
通过对 tsdb 和 exemplars 的合理配置,可以让 Prometheus 更好地存储和管理时间序列数据以及相关的示例数据,为监控和故障排查提供有力支持。
scrape_config
1 | job_name: <job_name> |
params
可选的 HTTP URL 参数
1 | params: |
假设你有一个 HTTP API,用于获取城市的天气信息。该 API 接受一些参数来指定查询的条件,例如城市名称、日期等。你可以使用 params 来设置这些参数,以便向 API 发送正确的请求。
1 | api: |
在这个例子中,params 定义了两个参数:city 和 date。city 参数的值为 ["Beijing", "Shanghai"],表示要查询北京和上海两个城市的天气信息。date 参数的值为 ["2025-03-26"],表示要查询 2025 年 3 月 26 日的天气信息。
当应用程序根据这个配置向 https://api.example.com/weather 发送请求时,它会将参数附加到 URL 中,形成类似 https://api.example.com/weather?city=Beijing&city=Shanghai&date=2025-03-26 的请求 URL。这样,API 服务器就可以根据这些参数来返回相应的天气数据。
查询
函数
- 数学运算函数:
- 绝对值函数
abs():将输入向量的样本值转换为绝对值。 - 向上取整函数
ceil():将样本值向上舍入到最接近的整数。 - 向下取整函数
floor():将样本值向下舍入到最接近的整数。 - 指数函数
exp():计算样本值的指数。 - 自然对数函数
ln()、二进制对数函数log2()、十进制对数函数log10():分别计算相应的对数。 - 平方根函数
sqrt():计算样本值的平方根。 - 符号函数
sgn():返回样本值的符号(1、-1 或 0)。 - 三角函数(
acos()、asin()、atan()等)和双曲函数(acosh()、asinh()、atanh()等):进行相应的三角和双曲运算,以弧度为单位,还有deg()和rad()用于度数和弧度的转换。
- 绝对值函数
- 时间相关函数:
- 获取当前时间的秒数
time()。 - 获取向量样本的时间戳
timestamp()。 - 返回一年中的某天
day_of_year()、一月中的某天day_of_month()、一周中的某天day_of_week()、一天中的小时hour()、一小时中的分钟minute()、一年中的月份month()、年份year()。 - 计算一个月的天数
days_in_month()。
- 获取当前时间的秒数
- 指标计算函数:
- 计算计数器的增加量
increase()、瞬时增加率irate()、平均增加率rate(),increase()和rate()可处理计数器重置,irate()基于最后两个数据点计算瞬时速率。 - 计算仪表的导数
deriv()、预测值predict_linear(),需注意deriv()和predict_linear()只能与仪表一起使用。 - 计算直方图相关指标的函数,如
histogram_avg()、histogram_count()、histogram_sum()、histogram_fraction()、histogram_quantile()、histogram_stddev()、histogram_stdvar(),这些函数仅作用于原生直方图,是实验性特征。 - 计算样本值变化次数
changes()、计数器重置次数resets()。
- 计算计数器的增加量
- 数据处理函数:
- 处理标签冲突的
honor_labels配置项,控制 Prometheus 对抓取数据和服务器端标签冲突的处理方式。 - 标签操作函数
label_join()用于连接标签值,label_replace()用于替换标签值。 - 数据平滑函数
double_exponential_smoothing(),需启用实验性功能标志,用于对时间序列进行平滑处理,只能与仪表一起使用。
- 处理标签冲突的
- 特殊函数:
absent()和absent_over_time()用于检查指标是否存在,在指标不存在时返回特定结果,可用于发出警报。info()是实验性函数,用于简化从 info 指标添加标签的操作,需启用实验性功能标志。scalar()将单元素向量转换为标量值,若向量元素不为 1 则返回NaN。
- 聚合函数:
- 包括
avg_over_time()、min_over_time()、max_over_time()、sum_over_time()、count_over_time()、quantile_over_time()、stddev_over_time()、stdvar_over_time()、last_over_time()、present_over_time()、mad_over_time()(需启用实验性功能标志)等,用于对范围向量进行聚合操作,部分函数可处理原生直方图,部分函数会忽略直方图样本。
- 包括
- 排序函数:
sort()按样本值升序排序,sort_desc()按样本值降序排序,sort_by_label()按指定标签值升序排序,sort_by_label_desc()按指定标签值降序排序,这些函数仅影响即时查询结果。
- 其他函数:
idelta()计算范围向量中最后两个样本的差值,只能与仪表一起使用。round()将样本值四舍五入到最接近的整数,可指定舍入的倍数。vector()将标量转换为无标签的向量。
存储
Prometheus 自带一个本地磁盘时间序列数据库,它以自定义的高效格式在本地存储数据。不过,它也支持与远程存储系统集成,用户可根据实际需求选择。
磁盘布局
1.数据块划分
摄入的样本会被分组存为 2 小时的块。每个 2 小时块对应的目录包含以下内容:
- chunks 子目录:存放该时间窗口内所有时间序列的样本。样本默认被分组到一个或多个区段文件中,每个区段文件最大为 512MB。
- 元数据文件(meta.json):记录该数据块的相关元数据信息。
- 索引文件(index):为度量名称和标签编制索引,方便快速定位 chunks 目录中的时间序列。
2. 删除记录处理
当有时间序列的删除记录时,不会立即从 chunk 段中删除数据,而是将删除记录存储在单独的 tombstone 文件中
3. 预写日志(WAL)
- 正在处理传入样本的当前块会保存在内存中,还未完全持久化。为防止崩溃导致数据丢失,使用预写日志(WAL)进行保护,在 Prometheus 服务器重启时可重放 WAL 中的数据。
- WAL 文件以 128MB 为单位分段存储在
wal目录下。这些文件包含尚未压缩的原始数据,所以比常规块文件大很多。 - Prometheus 至少会保留三个预写日志文件。对于高流量服务器,可能会保留三个以上的 WAL 文件,以确保至少有 2 小时的原始数据。
数据目录示例
以下是 Prometheus 服务器数据目录的示例结构:
1 | ./data |
- 以一串随机字符命名的目录代表不同的 2 小时数据块。
chunks_head目录存放当前正在处理的块的样本数据。wal目录存放预写日志文件和检查点文件。
部分块只有 meta.json 文件而无其他文件的原因
1.数据为空或未采集到数据
若在某个 2 小时的时间窗口内,没有任何样本数据被采集或者存储到该数据块,那么这个数据块可能就只有 meta.json 文件。meta.json 作为元数据文件,它记录了该数据块的基本信息,即便没有实际的样本数据,这个元数据文件依然会存在。
2.数据被清理或迁移
有可能在之前这个数据块是有数据的,不过经过了数据清理或者迁移操作后,相关的 chunks 目录、index 文件等都被移除了,只保留了 meta.json 文件用于记录该数据块曾经的元数据信息。
3.数据正在初始化
在数据块刚刚创建的时候,可能还处于初始化阶段,只有 meta.json 文件被创建,后续随着样本数据的不断采集和处理,才会逐步生成 chunks 目录、index 文件等。
数据压实
Prometheus 最初存储的是 2 小时的数据块,之后会在后台将这些小数据块压缩成更大的数据块。压实创建的新数据块,其涵盖的数据时间跨度最大为保留时间的 10% 或者 31 天,取两者中的较小值。
本地存储配置
Prometheus 提供了一些配置本地存储的重要标志:
--storage.tsdb.path:指定 Prometheus 数据库的写入位置,默认是data/。--storage.tsdb.retention.time:设置样本的存储时长,若未设置该标志和--storage.tsdb.retention.size,默认保留时间为 15 天。支持的时间单位有y(年)、w(周)、d(天)、h(小时)等。--storage.tsdb.retention.size:规定要保留的存储块的最大字节数,会优先删除最早的数据。默认是禁用状态,支持的字节单位有B、KB、MB等。--storage.tsdb.wal-compression:开启预写日志(WAL)的压缩功能,可使 WAL 大小减半,且几乎不增加额外的 CPU 负载。该标志在 2.11.0 版本引入,2.20.0 版本默认启用。若启用后将 Prometheus 降级到低于 2.11.0 的版本,需要删除 WAL。
容量规划与数据损坏处理
- 容量规划:Prometheus 平均每个样本仅需 1 - 2 字节的存储空间。可以使用公式
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample来粗略估算所需的磁盘空间。若要降低样本摄取速率,可减少抓取的时间序列或增加抓取间隔,减少序列数量可能更有效。 - 数据损坏处理:若本地存储损坏导致 Prometheus 无法启动,建议备份存储目录并从备份中恢复损坏的块目录。若没有备份,可删除损坏的文件,但这会导致相应时间范围内的数据丢失。同时,Prometheus 不支持不符合 POSIX 的文件系统用于本地存储,如 NFS(包括 AWS 的 EFS),建议使用本地文件系统以保证可靠性。
保留策略
若同时设置了时间和大小保留策略,会优先采用先触发的策略。过期块的清理在后台进行,最多可能需要两小时来删除过期块,且区块必须完全过期才会被删除。建议将保留大小设置为分配给 Prometheus 磁盘空间的 80 - 85%,以确保在磁盘满之前删除较早的数据。
远程存储集成
Prometheus 本地存储在可扩展性和持久性方面存在局限,因此提供了与远程存储系统集成的接口,集成方式有四种:
- Prometheus 可将提取的样本以 Remote Write 格式写入远程 URL。
- 可接收来自其他客户端的 Remote Write 格式的样本。
- 能以 Remote Read 格式从远程 URL 读取样本数据。
- 可以 Remote Read 格式返回客户端请求的样本数据。
远程读写协议采用 snappy 压缩的协议缓冲区编码的 HTTP 请求,读取协议尚未稳定。写入协议有 1.0 稳定版本和 2.0 实验版本,Prometheus 服务器均支持。Prometheus 提供了远程写入接收器和远程读取端点,分别为 /api/v1/write 和 /api/v1/read。不过,远程读取查询存在可扩展性限制,因为所有必要的数据都需先加载到 Prometheus 服务器进行处理。
服务发现
文件服务发现和 HTTP 服务发现是 Prometheus 中用于发现监控目标的两种不同机制。
1 | - job_name: 'node_exporter' |
文件服务发现(File - Based SD)
- 原理:文件发现是一种相对简单直接的服务发现方式。通过在本地指定一个或多个配置文件,文件内以特定格式定义监控目标的相关信息,Prometheus 会定期读取这些文件,根据文件内容发现监控目标。
- 配置示例:创建一个名为
targets.yml的文件,内容如下:
1 | - targets: |
上述配置中,定义了两个监控目标的 IP 地址和端口,同时为它们添加了 group: 'web - servers' 的标签。在 Prometheus 的配置文件 prometheus.yml 中,添加如下配置启用文件发现:
1 | scrape_configs: |
这表示 Prometheus 会每隔 5 分钟读取 targets.yml 文件,根据文件内容更新监控目标。
- 应用场景:适用于小型、相对静态的环境,比如传统数据中心内服务器变动不频繁的场景,或者在测试环境中方便快速配置少量监控目标。
Kubernetes 发现
- 原理:在 Kubernetes 集群环境中,Prometheus 利用 Kubernetes API 来实现服务发现。它通过监听 Kubernetes 资源对象(如 Pod、Service、Endpoint 等)的创建、删除、更新等事件,自动发现符合条件的监控目标。例如,当创建一个新的 Pod 且该 Pod 带有特定的用于监控的注解(Annotation)时,Prometheus 能立刻感知并将其纳入监控范围。
- 配置示例:在 Prometheus 的配置文件
prometheus.yml中进行如下配置:
1 | scrape_configs: |
上述配置中,指定了从 Kubernetes API 服务器获取 Pod 资源信息,通过 relabel_configs 对获取到的 Pod 信息进行筛选和转换,仅监控带有特定注解且符合条件的 Pod 。
- 应用场景:在以 Kubernetes 为基础的容器编排环境中广泛应用,像互联网公司大规模的微服务架构部署在 Kubernetes 集群中,可借助此机制实现对大量动态变化的容器化应用的自动监控 。
HTTP 服务发现(HTTP SD)
- 基本原理:Prometheus 定期通过 HTTP 或 HTTPS 协议向指定的端点发送请求,获取监控目标的信息。
- 更新频率:按照设置的
refresh_interval(默认 1 分钟)进行更新。每隔这个时间间隔,Prometheus 就会向 HTTP SD 端点发送 GET 请求,获取最新的监控目标列表。 - 数据格式:要求返回的内容为 JSON 格式。例如:
1 | [ |
- 传输方式:通过 HTTP 或 HTTPS 协议进行数据传输。Prometheus 向配置好的 HTTP SD 端点发送请求,获取监控目标信息。
- 安全性:支持多种安全认证方式,包括 TLS 认证、基本认证(Basic auth)、授权头(Authorization header)以及 OAuth2 等,以确保只有授权的客户端才能访问 HTTP SD 端点并获取监控目标信息。
consul发现
安装
1 | docker run -d --name consul -p 8500:8500 consul:1.14.5 |
注册consul
1 | curl -X PUT -d '{"id": "node1"," name": "node_exporter", "address": "node_exporter", "port": 9100,"tags": ["exporter"],"meta": {"job":"node_exporter","instance":"Prometheus服务器"},“check”: [{"http": "http://192.168.8.130:9100/metrics", "interval": 5s}]}' http://localhost:8500/v1/agent/service/register |
prometheus.yml
1 | global: |
relabeling
在 Prometheus 里,重新标记(relabeling)机制是一项极为关键的特性,它能让你在数据抓取与处理期间对标签进行修改、添加或删除操作,从而实现灵活的监控配置。下面从使用场景、工作流程、常用的重新标记配置以及示例几个方面进行介绍。
使用场景
- 数据清理:当从目标服务获取的标签包含不必要的信息时,可借助重新标记机制将其去除。
- 标签标准化:不同服务或许会使用不同的标签命名规范,通过重新标记能让所有标签统一命名。
- 动态目标选择:依据标签值来决定是否抓取某个目标。
工作流程
重新标记机制在 Prometheus 中有两个主要阶段起作用:目标发现和样本采集。
- 目标发现阶段:在从服务发现机制(如 Consul、Kubernetes 等)获取目标后,Prometheus 会根据重新标记配置对目标的标签进行修改。这可以帮助过滤掉不需要的目标,或者为目标添加额外的标签。
- 样本采集阶段:在采集到样本数据后,Prometheus 会再次应用重新标记配置来修改样本的标签。这可以用于修改或添加标签,以便在后续的查询和可视化中更方便地使用。
常用的重新标记配置
重新标记配置通过 relabel_configs 字段来定义,它是一个数组,每个元素是一个重新标记规则。常用的配置参数如下:
source_labels:指定要用于匹配的源标签列表。separator:指定源标签之间的分隔符,默认为;。regex:用于匹配源标签值的正则表达式。target_label:指定要修改的目标标签。replacement:用于替换匹配到的标签值的字符串,支持使用正则表达式的捕获组。action:指定重新标记的操作类型,常见的有replace、keep、drop、labelmap等。
示例
下面是一个简单的 prometheus.yml 配置文件示例,展示了重新标记机制的使用:
1 | scrape_configs: |
这个示例中:
- 第一条规则从
__address__标签中提取主机名,并将其赋值给instance标签。 - 第二条规则只保留
job标签值为my_service的目标。
通过这些配置,你可以根据实际需求对 Prometheus 的标签进行灵活的管理和处理。
Prometheus实战
Linux服务器监控
1.服务器安装node_exporter
1 | version: '3.3' |
1 | docker-compose up -d |
修改服务端prometheus.yml
1 | static_config: |
热重启prometheus
1 | curl -X POST http://localhost:9090/-/reload |
2.常用监控指标
| 指标分类 | 指标名称 | 含义 |
|---|---|---|
| CPU | node_cpu_seconds_total |
CPU 在不同模式(如用户态、内核态等)下花费的总时间,可按 cpu 标签区分不同 CPU 核心,如 node_cpu_seconds_total{cpu="0"} 表示 CPU 0 的情况 |
| CPU | node_load1 |
系统在过去 1 分钟内的平均负载 |
| CPU | node_load5 |
系统在过去 5 分钟内的平均负载 |
| CPU | node_load15 |
系统在过去 15 分钟内的平均负载 |
| 内存 | node_memory_MemTotal_bytes |
系统物理内存的总量(以字节为单位) |
| 内存 | node_memory_MemFree_bytes |
系统当前空闲的物理内存量(以字节为单位) |
| 内存 | node_memory_MemAvailable_bytes |
系统可用于分配给新进程的物理内存量(以字节为单位) |
| 内存 | node_memory_Buffers_bytes |
系统用于缓存磁盘块的内存量(以字节为单位) |
| 内存 | node_memory_Cached_bytes |
系统用于缓存文件内容的内存量(以字节为单位) |
| 磁盘 | node_disk_read_bytes_total |
磁盘累计读取的字节数 |
| 磁盘 | node_disk_written_bytes_total |
磁盘累计写入的字节数 |
| 磁盘 | node_disk_io_time_seconds_total |
磁盘进行 I/O 操作所花费的总时间(以秒为单位) |
| 网络 | node_network_receive_bytes_total |
网络接口累计接收的字节数 |
| 网络 | node_network_transmit_bytes_total |
网络接口累计发送的字节数 |
| 网络 | node_network_receive_errs_total |
网络接口接收数据包时发生错误的总数 |
| 网络 | node_network_transmit_errs_total |
网络接口发送数据包时发生错误的总数 |
| 进程 | node_procs_running |
当前正在运行的进程数量 |
| 进程 | node_procs_blocked |
当前处于阻塞状态的进程数量 |
| 文件系统 | node_filesystem_size_bytes |
文件系统的总大小(以字节为单位) |
| 文件系统 | node_filesystem_free_bytes |
文件系统的空闲空间大小(以字节为单位) |
| 文件系统 | node_filesystem_avail_bytes |
文件系统中可供普通用户使用的空闲空间大小(以字节为单位) |
mysql监控
docker-compose.yml文件
1 | version: '3.1' |
1 | docker-compose up -d |
进入容器
1 | docker exec -it mysql mysql -uroot -p |
创建用户
1 | CREATE USER 'exporter'@'%' IDENTIFIED BY 'password' WITH MAX_USER_CONNECTIONS 3; |
验证
1 | docker exec -it mysql mysql -uexporter -p |
docker-mysql-exporter
1 | version: '3.3' |
参数详解
--collect.info_schema.processlist
此参数的作用是让mysqld-exporter从 MySQL 的information_schema.processlist表收集数据。这个表记录了当前 MySQL 服务器上正在执行的所有线程的信息,像线程 ID、用户、主机、执行的查询等。借助收集这些数据,能够对 MySQL 服务器上的活动查询和线程进行监控。--collect.info_schema.innodb_metrics
该参数会让mysqld-exporter从information_schema.innodb_metrics表收集 InnoDB 存储引擎的性能指标。这些指标涵盖了锁等待、事务处理、缓冲池使用情况等多方面的信息,有助于深入了解 InnoDB 存储引擎的运行状况。--collect.info_schema.tablestats
使用这个参数,mysqld-exporter会从information_schema.tablestats表收集表的统计信息,比如表中的行数、数据长度、索引长度等。这些统计信息可用于评估表的大小和使用情况。--collect.info_schema.tables
它的作用是让mysqld-exporter从information_schema.tables表收集表的元数据,包括表名、存储引擎、创建时间、更新时间等。这些元数据有助于对数据库中的表进行管理和监控。--collect.info_schema.userstats
该参数会使mysqld-exporter从information_schema.userstats表收集用户的统计信息,像用户执行的查询次数、查询时间等。这些信息有助于了解不同用户对数据库的使用情况。--collect.engine_innodb_status
这个参数让mysqld-exporter收集 InnoDB 存储引擎的状态信息。这些信息包含了 InnoDB 的内部状态、锁信息、事务信息等,对排查 InnoDB 相关的问题很有帮助。"--mysqld.username=exporter:password"
此参数用于指定连接 MySQL 数据库时使用的用户名和密码。"--mysqld.address=192.168.8.131:3306"
该参数用于指定要监控的 MySQL 数据库的地址和端口。在这个例子中,MySQL 服务器的 IP 地址是192.168.8.131,端口号是3306。
MySQLd Exporter 打开连接验证是否运行成功
常用监控指标
| 监控指标 | 含义 |
|---|---|
| mysql_up | 反映服务器是否在线 |
| mysql_global_status_uptime | 服务器运行时长,单位为秒 |
| delta(mysql_global_status_bytes_received[1m]) | 1 分钟内网络接收的字节数 |
| delta(mysql_global_status_bytes_sent[1m]) | 1 分钟内网络发送的字节数 |
| mysql_global_status_threads_connected | 当前的客户端连接数 |
| mysql_global_variables_max_connections | 允许的最大连接数 |
| mysql_global_status_threads_running | 正在执行命令(非 sleep 状态)的客户端连接数 |
| delta(mysql_global_status_aborted_connects[1m]) | 1 分钟内客户端建立连接失败的连接数 |
| delta(mysql_global_status_aborted_clients[1m]) | 1 分钟内客户端连接后未正常关闭的连接数 |
| delta(mysql_global_status_commands_total{command=”xx”}[1m]) | 1 分钟内各种命令的执行次数 |
| delta(mysql_global_status_handlers_total{handler=”xx”}[1m]) | 1 分钟内各种操作的执行次数 |
| delta(mysql_global_status_handlers_total{handler=”commit”}[1m]) | 1 分钟内 commit 操作的执行次数 |
| delta(mysql_global_status_table_locks_immediate[1m]) | 1 分钟内请求获取锁且立即获得的请求数 |
| delta(mysql_global_status_table_locks_waited[1m]) | 1 分钟内请求获取锁但需要等待的请求数 |
| delta(mysql_global_status_queries[1m]) | 1 分钟内的查询数 |
| delta(mysql_global_status_slow_queries[1m]) | 1 分钟内的慢查询数 |
| mysql_global_status_innodb_page_size | InnoDB 数据页的大小,单位为字节 |
| mysql_global_variables_innodb_buffer_pool_size | InnoDB_buffer_pool 的限制体积 |
| mysql_global_status_buffer_pool_pages{state=”data”} | 包含数据的数据页数(包括洁页、脏页) |
| mysql_global_status_buffer_pool_dirty_pages | 脏页数 |
告警规则
1 | groups: |
检查配置文件
1 | docker exec -it prometheus promtool check config /etc/prometheus/prometheus.yml |
黑盒监控
把exporter安装到监控目标主机上,就是白盒监控。
监控他人主机运行,给目标主机发送请求,探测状态,就是黑盒监控
监控原理
- 黑盒监控:黑盒监控将被监控对象视为一个不透明的 “黑盒”,只关注其输入和输出,通过向被监控系统发送特定的探测请求,然后根据返回的响应来判断系统的运行状态,不考虑内部的运行机制和实现细节。
- 白盒监控:白盒监控则是基于对被监控系统内部结构和运行机制的了解,通过在系统内部植入监控探针或利用系统自身暴露的监控接口,来获取系统内部的各种指标和状态信息,从而实现对系统的深入监控。
数据来源
- 黑盒监控:数据主要来源于外部对系统的探测,比如通过 HTTP 请求、ICMP 包等方式获取系统的响应信息,包括响应码、响应时间、数据包丢失率等。
- 白盒监控:数据来自于被监控系统内部,例如应用程序的性能指标(如 CPU 使用率、内存占用、数据库查询执行时间、缓存命中率)、系统日志、进程状态等。
应用场景
- 黑盒监控:常用于监控网络设备、服务器的连通性、外部服务的可用性等场景。比如,监控一个网站的可用性,可以通过向网站的域名发送 HTTP 请求,根据返回的状态码来判断网站是否正常运行。如果返回 200 OK,表示网站正常;如果返回 500 Internal Server Error 等错误码,则表示网站可能出现了问题。
- 白盒监控:适用于对应用程序和系统内部性能进行深入分析和优化的场景。以一个电商网站为例,白盒监控可以收集数据库的查询性能指标,了解哪些查询语句执行时间较长,从而针对性地进行优化;还可以监控应用服务器的内存使用情况,及时发现内存泄漏等问题。
配置复杂度
- 黑盒监控:配置相对简单,只需要定义好探测的目标地址、探测方法(如 HTTP、ICMP 等)以及相关的阈值即可。例如,使用 Prometheus 的 Blackbox Exporter 监控一个 Web 服务,只需配置要监控的 URL 和期望的响应状态码等基本信息。
- 白盒监控:配置通常较为复杂,需要在被监控系统中安装和配置监控代理或插件,并且要根据不同的应用和系统类型,配置相应的监控指标采集规则。例如,在 Java 应用中使用 JMX Exporter 来暴露 JVM 的性能指标,需要对 JMX 进行详细的配置,包括选择要监控的 MBean 对象和属性等。
对被监控系统的影响
- 黑盒监控:因为是从外部进行探测,对被监控系统的性能影响通常较小,除非探测的频率非常高或者探测请求本身对系统资源消耗较大。
- 白盒监控:由于需要在系统内部运行监控组件,可能会对被监控系统的性能产生一定的影响,尤其是在采集大量详细指标时。例如,频繁地读取系统日志或收集大量的性能指标数据,可能会增加系统的 CPU 和 I/O 开销。
Blackbox Exporter 支持多种探测方式,下面是不同探测方式及其在 blackbox.yml 中的配置示例,和 Prometheus 配置。
1. HTTP 探测
HTTP 探测可用于检查网站的可用性、响应时间等。
http_2xx配置示例
blackbox.yml 配置
1 | modules: |
prober: http
- 含义:明确使用 HTTP 作为探测方式。Blackbox Exporter 支持多种探测方式,像 HTTP、TCP、ICMP 等,此参数表明本次探测采用 HTTP 请求。
- 必要性:必要参数。它是指定探测类型的关键,若缺少该参数,Blackbox Exporter 就无法知晓采用何种方式进行探测。
timeout: 5s
- 含义:设定探测请求的超时时间为 5 秒。若在 5 秒内未收到服务器响应,就会判定探测失败。
- 必要性:非必要参数。若未设置该参数,Blackbox Exporter 会使用默认的超时时间 10 秒。
http 子配置块
valid_status_codes: [200]
- 含义:规定只有当服务器返回的 HTTP 状态码为 200 时,才认为探测成功。可根据需求添加其他状态码,例如
[200, 201, 204]。 - 必要性:非必要参数。若不设置该参数,默认所有状态码都被视为有效。在实际监控中,通常需要明确指定期望的状态码。
method: GET
- 含义:指定使用 HTTP GET 方法发送探测请求。HTTP 还有 POST、PUT、DELETE 等其他方法,可根据实际情况进行修改。
- 必要性:非必要参数。默认使用 GET 方法,若需要使用其他方法,就需要设置该参数。
preferred_ip_protocol: "ip4"
- 含义:优先使用 IPv4 协议进行通信。若目标服务器同时支持 IPv4 和 IPv6,会优先选择 IPv4 地址进行连接。
- 必要性:非必要参数。若不设置该参数,会使用系统默认的 IP 协议。
no_follow_redirects: false
- 含义:设置是否跟随 HTTP 重定向。
false表示跟随重定向,即当服务器返回 3xx 状态码时,会继续访问重定向后的地址;true则表示不跟随重定向。 - 必要性:非必要参数。默认会跟随重定向,若不需要跟随重定向,可将其设置为
true。
fail_if_ssl: false
- 含义:设定若服务器使用 SSL/TLS 加密连接,是否判定探测失败。
false表示即使使用 SSL/TLS 也不判定失败;true则表示若使用 SSL/TLS 就判定失败。 - 必要性:非必要参数。通常情况下,不需要因为服务器使用 SSL/TLS 而判定失败,所以默认设置为
false。
fail_if_not_ssl: false
- 含义:规定若服务器未使用 SSL/TLS 加密连接,是否判定探测失败。
false表示即使不使用 SSL/TLS 也不判定失败;true则表示若不使用 SSL/TLS 就判定失败。 - 必要性:非必要参数。默认情况下,不要求服务器必须使用 SSL/TLS 连接。
tls_config 子配置块
insecure_skip_verify: false
- 含义:设置是否跳过 SSL/TLS 证书验证。
false表示不跳过验证,会验证服务器的 SSL/TLS 证书是否有效;true则表示跳过验证,即使证书无效也会继续连接。 - 必要性:非必要参数。在生产环境中,建议保持
false以确保通信安全;在测试环境中,若服务器使用的是自签名证书,可将其设置为true。
prometheus.yml 配置
1 | - job_name: 'blackbox_http' |
http_post_2xx 配置示例
1 | modules: |
在 http_post_2xx 配置中,除了把 method 设置为 POST 外,还可能需要配置 headers 和 body 参数。headers 用于设置请求头,例如指定请求体的内容类型;body 用于设置请求体,即要提交的数据。
2. TCP 探测
TCP 探测用于检查目标主机的 TCP 端口是否开放。
blackbox.yml 配置
1 | modules: |
prometheus.yml 配置
1 | - job_name: 'blackbox_tcp' |
3. ICMP 探测
ICMP 探测用于检查目标主机的连通性。
blackbox.yml 配置
1 | modules: |
prometheus.yml 配置
1 | - job_name: 'blackbox_icmp' |
4. DNS 探测
DNS 探测用于检查 DNS 解析是否正常。
blackbox.yml 配置
1 | modules: |
prometheus.yml 配置
1 | - job_name: 'blackbox_dns' |
5. SMTP 探测
SMTP 探测用于检查 SMTP 服务器是否正常工作。
blackbox.yml 配置
1 | modules: |
prometheus.yml 配置
1 | - job_name: 'blackbox_smtp' |
6. POP3 探测
POP3 探测用于检查 POP3 服务器是否正常工作。
blackbox.yml 配置
1 | modules: |
prometheus.yml 配置
1 | - job_name: 'blackbox_pop3' |
7. IMAP 探测
IMAP 探测用于检查 IMAP 服务器是否正常工作。
blackbox.yml 配置
1 | modules: |
prometheus.yml 配置
1 | - job_name: 'blackbox_imap' |
部署
1 | modules: |
直接运行:
1 | docker run -d --restart=always --name blackbox-exporter -p 9115:9115 -v /data/blackbox_exporter:/etc/blackbox_exporter prom/blackbox-exporter:v0.19.0 --config.file=/etc/blackbox_exporter/config.yml |
添加prometheus.yml文件
1 | #http配置 |
常用指标
1 | probe_success,是否探测成功(取值 1、0 分别表示成功、失败) |
触发器配置
1 | groups: |
Pushgateway
1 | docker run -d -p 9091:9091 --name pushgateway prom/pushgateway |
prometheus.yml 增加
1 | - job_name: 'pushgateway' |
1 | curl -X POST http://localhost:9090/-/reload |
curl 推送消息
- 向{ job=”some_job” } 添加单条数据:
1 | echo “some_metric 3.14” | curl --data-binary @- http://192.168.8.130:9091/metrics/job/some_job |
- 删除某个组下的某个实例的所有数据
1 | curl -X DELETE http://192.168.8.130:9091/metrics/job/some_job/instance/some_instance |
- 删除某个组下的所有数据
1 | curl -X DELETE http://192.168.8.130:9091/metrics/job/some_job |
python 推送消息
1 | apt install python3-pip |
1 | pip install prometheus_client |
告警
邮箱告警
略,见上文
企业钉钉告警
企业钉钉创建群聊自定义机器人
/data/docker-prometheus/prometheus-webhook-dingtalk/config.yml文件
1 | targets: |
docker-compose创建
1 | version: '3.3' |
alertmanager的config.yml文件新增
1 | route: |
修改全局receiver 为 dingtalk
企业微信告警
创建群机器人 拷贝webhook地址:
1 |
docker_compose
1 | version: "2" |
1 | receivers: |
飞书告警
项目链接:
- GitHub - XUJiahua/alertmanager-webhook-feishu
该项目基于 Go 语言开发,支持飞书机器人的消息模板定制、@指定用户、签名校验等功能,适用于 Kubernetes 等云原生环境。
使用方式:
创建飞书机器人:
在飞书群聊中添加自定义机器人,获取 Webhook URL。配置 Alertmanager:在alertmanager.yml中定义接收器:
1
2
3
4
5receivers:
- name: 'feishu'
webhook_configs:
- url: 'http://<alertmanager-webhook-feishu服务地址>/hook/<自定义群组名>'
send_resolved: true部署工具:
通过 Docker 或二进制包部署,配置飞书机器人的 Webhook URL 和模板文件。
Explore Docker’s Container Image Repository | Docker Hub
特性:
- 支持多机器人管理
- 自定义消息模板(基于 Go Template)
- 支持 @ 特定用户(需获取用户
open_id) - 提供 Helm Chart 简化 Kubernetes 部署
问题解答:
1、expoeters demo 本地运行 了解exporters的原理
例如,若当前时间是 10:00:00,Exporter 在 9:59:55 采集了数据,当 Prometheus 在 10:00:00 来拉取时,Exporter 就把 9:59:55 采集到的数据返回
时间戳的添加
时间戳是由 Prometheus 在抓取指标数据时自动添加的,而不是由 Exporter 负责添加。当 Prometheus 从 Exporter 抓取到指标数据后,会为每个样本添加上当前的时间戳,以此来记录该样本的采集时间。所以,即便你在自定义 Exporter 时没有添加时间戳,Prometheus 也会自动处理并为数据加上时间戳,这样就能在 Prometheus 中基于时间序列进行查询和分析了。
采样时间的设置主体
采样时间是由 Prometheus 配置文件设置的,而不是由 Exporter 决定。在 Prometheus 的配置文件里,scrape_interval 参数用于设定 Prometheus 从各个 Exporter 抓取指标数据的时间间隔。示例如下:
1 | global: |
虽然你自定义的 Exporter 定义了每 15 秒获取一次指标,但这只是 Exporter 自身收集指标的频率。Prometheus 会按照自己配置的 scrape_interval 去抓取 Exporter 提供的指标数据。比如,若 Exporter 每 15 秒更新一次指标,而 Prometheus 的 scrape_interval 设为 1 分钟,那么 Prometheus 还是会每分钟去抓取一次 Exporter 上的数据。
- MySQL
- MySQL 官方文档 - INFORMATION_SCHEMA:详细介绍了
INFORMATION_SCHEMA数据库中的各个表,包括与性能相关的表,如PROCESSLIST等。 - MySQL 官方文档 - PERFORMANCE_SCHEMA:对
PERFORMANCE_SCHEMA中用于性能监控的表和功能进行了全面说明。 - MySQL 官方文档 - sys schema:介绍了
sys模式下与性能分析相关的视图和表,能帮助用户更方便地查看和分析性能数据。
- MySQL 官方文档 - INFORMATION_SCHEMA:详细介绍了
- PostgreSQL
- PostgreSQL 官方文档 - pg_stat_activity:对
pg_stat_activity视图进行了详细解释,包括其各个字段的含义和用途。 - PostgreSQL 官方文档 - pg_stat_statements:说明了
pg_stat_statements扩展的功能和相关表结构,用于收集和分析查询的执行统计信息。 - PostgreSQL 官方文档 - pg_stat_database:介绍了
pg_stat_database视图,提供了关于数据库级别的统计信息,如连接数、事务数等。
- PostgreSQL 官方文档 - pg_stat_activity:对
- CockroachDB
- CockroachDB 官方文档 - System Tables:介绍了 CockroachDB 中的系统表,包括与性能监控相关的表,如
crdb_internal.cluster_contention_events等。 - CockroachDB 官方文档 - Monitoring and Metrics:提供了关于 CockroachDB 性能监控的整体指导,包括如何使用内置的性能指标表以及相关的监控工具。
- CockroachDB 官方文档 - System Tables:介绍了 CockroachDB 中的系统表,包括与性能监控相关的表,如
2、从哪些角度对数据库制定监控规则?适用性
mysql
服务可用性:实时判断 MySQL 实例、从库线程是否正常运行,确保服务稳定。
资源利用:针对连接数、线程运行、文件打开数量以及预准备语句的使用,进行合理调配与监控。
复制性能:通过监控复制延迟,保障数据同步的及时性和准确性。
查询性能:检测慢查询和 QPS,优化数据库查询效率。
日志状态:关注 InnoDB 日志写入等待,确保日志系统稳定运行。
系统状态:捕捉 MySQL 服务重启,以及 InnoDB 强制恢复等关键系统状态变化。
参数优化:针对 InnoDB 历史长度过高等问题,给出优化建议 。
pg
服务状态:检查服务是否宕机、重启,以及监控工具是否报错。
连接管理:针对连接数过多、过少,以及锁资源使用过量的情况告警。
数据维护:监测表的自动清理与分析操作是否按时执行。
事务性能:关注事务提交率、回滚率,以及事务 ID 消耗速度。
异常情况:对死锁、语句超时等数据库异常进行预警。
复制同步:检测复制槽状态,以及复制延迟是否过高。
配置与优化:跟踪配置变更,避免 SSL 压缩带来的问题,并处理表和索引的膨胀 。
mangodb
服务可用性:通过 mongodb_up 判断实例是否宕机,利用 mongodb_rs_members_health 监测副本集成员健康状况。
复制性能:监控复制延迟,若超过 10 秒则告警;检查复制余量,余量小于等于 0 时告警;同时关注副本集成员状态码异常情况。
资源使用:当打开的游标数量超过 10k 或游标超时过多时发出警告;连接数使用超过 80% 也会告警;虚拟内存使用率过高(虚拟与映射内存比值大于 3)时给出提醒。
备份情况:若 MongoDB 备份失败,会触发严重告警。
3、直方图 和 summary 时间窗口有没有默认值?必要要手动通过中括号指定吗?不填行不行?
在 Prometheus 中,对于直方图(Histogram)和摘要(Summary)指标,如果不填时间窗口,默认情况下会返回当前时刻最新的值。
- 直方图:以
http_request_duration_seconds_bucket为例,http_request_duration_seconds_bucket{le="0.1"} = 20表示当前时间点,请求持续时间小于等于 0.1 秒的请求数量为 20。这里没有指定时间窗口,就是获取最新的统计数据。 - 摘要:类似地,对于摘要指标,如果不指定时间窗口,也是返回当前最新的汇总数据,比如
http_request_duration_seconds_sum(请求持续时间的总和)、http_request_duration_seconds_count(请求的总次数)等指标,会返回当下的累计值。
不填时间窗口是可行的,此时会按照默认行为返回当前最新的指标数据,适用于只关心最新状态而不涉及历史数据查询的场景。但如果想要分析一段时间内的数据变化趋势或进行历史数据的统计分析,就需要手动通过中括号指定时间窗口了,如[5m]表示过去 5 分钟内的数据。
4、prometheus提供的python客户端,做了一些封装,提供了哪些方法?
4n4nd/prometheus-api-client-python: A python wrapper for the prometheus http api
Python 客户端库 prometheus_api_client
prometheus_api_client 是一个用于与 Prometheus 进行交互的 Python 库,它对 Prometheus 的 API 进行了封装,提供了一些方便的方法:
PrometheusConnect类:用于创建与 Prometheus 服务器的连接。构造函数接受url参数指定 Prometheus 服务器的地址,disable_ssl参数用于设置是否禁用 SSL 验证(默认为False)。custom_query方法:用于执行自定义的 PromQL 查询。接受一个 PromQL 查询字符串作为参数,返回查询结果。结果是一个包含查询数据的 Python 字典,格式遵循 Prometheus 的 API 响应结构。- 其他方法:除了
custom_query外,还提供了如get_metric_range_data等方法,用于查询一段时间范围内的指标数据。get_metric_range_data方法接受query(查询语句)、start_time(开始时间)、end_time(结束时间)和step(时间步长)等参数。
Java 代码示例分析
在你提供的 Java 代码中,==没有使用专门的 Prometheus 客户端库,而是直接使用 OkHttpClient 来发送 HTTP 请求到 Prometheus 的 API 端点==。具体步骤如下:
- 创建
OkHttpClient对象:OkHttpClient是一个强大的 HTTP 客户端库,用于发送 HTTP 请求。 - 构建请求:使用
Request.Builder构建一个GET请求,指定 Prometheus 的查询 API 端点(http://localhost:9090/api/v1/query?query=node_network_transmit_bytes_total)。 - 发送请求并处理响应:通过
client.newCall(request).execute()发送请求,并根据响应状态码处理响应数据。如果请求成功,读取并打印响应体;否则,打印错误信息。
5、pushgetway 数据汇总是什么? 持久化是什么意思?
Pushgateway 数据汇总
场景描述
假设你有一个分布式数据库系统,由多个数据库节点组成,用于处理不同地区的业务数据。为了监控这些数据库节点的运行状态,你会在每个节点上收集一些关键的性能指标,如每秒查询数(QPS)、磁盘 I/O 使用率、内存使用率等。然而,Prometheus 默认采用拉取(pull)模型来收集指标数据,而有些数据库节点可能由于网络限制或其他原因,不适合被 Prometheus 直接拉取数据。这时,就可以使用 Pushgateway 来进行数据汇总。
具体流程
- 数据收集:在每个数据库节点上,运行一个监控脚本或者程序,定期收集该节点的性能指标。例如,在一个 MySQL 数据库节点上,使用 Python 脚本结合
psutil库收集内存使用率,使用mysql -e命令查询 QPS 等信息。
1 | import psutil |
- 数据推送:每个数据库节点将收集到的指标数据推送到 Pushgateway。Pushgateway 会将这些来自不同节点的数据汇总存储在自己的内存中。
- Prometheus 拉取:Prometheus 定期从 Pushgateway 拉取汇总后的指标数据,进行存储和分析。在 Prometheus 的配置文件中,添加如下配置:
1 | scrape_configs: |
好处
通过 Pushgateway 进行数据汇总,Prometheus 只需要与 Pushgateway 进行通信,而不需要与每个数据库节点单独通信,减少了网络复杂性和 Prometheus 的负载。
Pushgateway 持久化
场景描述
在上述分布式数据库系统中,某个数据库节点由于硬件故障需要进行维护,维护期间该节点会被临时下线。在节点下线之前,它最后一次推送的监控数据会被 Pushgateway 接收并持久化存储。
具体表现
- 数据保存:Pushgateway 会将接收到的监控数据保存到本地磁盘上的文件中。即使 Pushgateway 重启或者所在的服务器发生故障,这些数据也不会丢失。例如,Pushgateway 可能会将数据以文本格式存储在
/var/lib/pushgateway/metrics文件中。 - 旧数据问题:由于 Pushgateway 会持久化存储数据,即使数据库节点已经下线,Prometheus 仍然会从 Pushgateway 拉取到该节点的旧监控数据。这可能会导致监控系统中出现一些误导性的信息,例如显示一个已经下线的节点仍然有 QPS 数据。
- 手动清理:为了避免旧数据的干扰,需要手动清理 Pushgateway 中不需要的数据。可以使用 Pushgateway 的 HTTP API 来删除特定作业或实例的指标数据。例如,使用
curl命令删除mysql_node作业下node1实例的指标数据:
1 | curl -X DELETE http://pushgateway.example.com:9091/metrics/job/mysql_node/instance/node |
假设你有一个批处理作业,它的运行时间非常短,可能就几秒钟。在这种情况下,Prometheus 可能无法及时拉取到该作业的指标数据。此时,你可以在作业结束时把指标数据推送给 Pushgateway,然后让 Prometheus 从 Pushgateway 拉取数据。以下是一个简单的 Python 示例,展示了如何把指标数据推送给 Pushgateway:
1 | from prometheus_client import CollectorRegistry, Gauge, push_to_gateway |
- 数据覆盖:Pushgateway 是基于标签(label)来存储指标数据的,若同一个标签组合的指标数据被多次推送,后面的数据会覆盖前面的数据。
- 数据清理:Pushgateway 不会自动清理过期的数据,所以需要定期清理不再使用的数据,以避免占用过多的存储空间。
6、除了163邮箱,是否支持其他的邮箱,qq邮箱、西电邮箱等
- Gmail:作为全球广泛使用的邮箱服务,Gmail 支持 SMTP 协议。用户可以通过配置 SMTP 服务器地址(smtp.gmail.com)和端口(通常为 587 或 465)来使用 SMTP 功能发送邮件。
- Outlook:包括Outlook.com以及企业版的 Exchange Online 等都支持 SMTP。其 SMTP 服务器地址为smtp.office365.com,端口一般为 587。
- QQ 邮箱:国内常用的邮箱之一,QQ 邮箱也支持 SMTP。SMTP 服务器地址为smtp.qq.com,端口为 465 或 587。用户需要在邮箱设置中开启 SMTP 服务,并生成授权码来使用 SMTP 功能。
- 163 邮箱:163 邮箱是网易旗下的邮箱服务,支持 SMTP 协议。SMTP 服务器地址为smtp.163.com,端口为 25、465 或 587。
- 搜狐邮箱:搜狐邮箱也提供 SMTP 服务,其 SMTP 服务器地址为smtp.sohu.com,端口一般为 25。
7、告警的分组、抑制、去重;
8、webhook原理 & 飞书告警中心对接
Webhook 是一种允许应用程序或系统在特定事件发生时,通过 HTTP 协议将相关数据自动发送到其他应用程序或系统的机制。
简单来说,webhook就是传话人,将告警转发给群聊人员
9、为什么prometheus数据要有这个label标签
- 唯一标识时间序列:在 Prometheus 里,指标名和标签组合起来能唯一标识一个时间序列。不同标签值的相同指标名代表不同的时间序列。例如
http_requests_total{method="GET", handler="/api/users"}和http_requests_total{method="POST", handler="/api/users"}是两个不同的时间序列,分别记录了不同 HTTP 请求方法下的请求总数。
一、飞书告警工具:alertmanager-webhook-feishu
项目链接:
- GitHub - XUJiahua/alertmanager-webhook-feishu
该项目基于 Go 语言开发,支持飞书机器人的消息模板定制、@指定用户、签名校验等功能,适用于 Kubernetes 等云原生环境。
使用方式:
创建飞书机器人:
在飞书群聊中添加自定义机器人,获取 Webhook URL。配置 Alertmanager:在alertmanager.yml中定义接收器:
1
2
3
4
5receivers:
- name: 'feishu'
webhook_configs:
- url: 'http://<alertmanager-webhook-feishu服务地址>/hook/<自定义群组名>'
send_resolved: true部署工具:
通过 Docker 或二进制包部署,配置飞书机器人的 Webhook URL 和模板文件。
特性:
- 支持多机器人管理
- 自定义消息模板(基于 Go Template)
- 支持 @ 特定用户(需获取用户
open_id) - 提供 Helm Chart 简化 Kubernetes 部署
二、其他常用软件的告警集成工具
1. 钉钉:prometheus-webhook-dingtalk
- 项目链接:GitHub - timonwong/prometheus-webhook-dingtalk
该工具支持钉钉机器人的消息模板、加签认证、Markdown 格式等,社区活跃度高,文档完善。
2. 企业微信:webhook-wechat
- 项目链接:GitHub - prometheus-operator/webhook-wechat
官方维护的企业微信告警工具,支持消息模板和会话机器人。
3. Slack:官方 Webhook 集成
配置方式:
在 Alertmanager 中直接配置 Slack Webhook URL:
1
2
3
4
5receivers:
- name: 'slack'
slack_configs:
- api_url: 'https://hooks.slack.com/services/your-webhook-token'
channel: '#alerts'
4. Microsoft Teams:官方 Webhook 集成
配置方式:
在 Teams 频道中添加 Incoming Webhook,获取 URL 后配置到 Alertmanager:
1
2
3
4receivers:
- name: 'teams'
webhook_configs:
- url: 'https://outlook.office.com/webhook/your-webhook-id'
5. Email:Alertmanager 内置支持
配置方式:在alertmanager.yml中配置 SMTP 服务器:
1
2
3
4
5
6
7
8
9global:
smtp_smarthost: 'smtp.example.com:587'
smtp_from: 'alerts@example.com'
smtp_auth_username: 'user'
smtp_auth_password: 'password'
receivers:
- name: 'email'
email_configs:
- to: 'admin@example.com'
6. PagerDuty:官方集成
- 项目链接:PagerDuty Prometheus Integration
通过 PagerDuty 的 Events API 实现告警通知,支持事件升级策略。
7. Opsgenie:官方集成
配置方式:在 Alertmanager 中配置 Opsgenie API Key:
1
2
3
4
5receivers:
- name: 'opsgenie'
opsgenie_configs:
- api_key: 'your-api-key'
region: 'us'
8. Telegram:第三方工具 prometheus-alertmanager-telegram
- 项目链接:GitHub - InVisionApp/prometheus-alertmanager-telegram
支持通过 Telegram Bot 发送告警消息,支持模板和群组通知。
三、通用集成方案:Webhook 自定义
若上述工具无法满足需求,可通过 通用 Webhook 实现任意平台的告警集成。以飞书为例:
创建飞书机器人,获取 Webhook URL。
配置 Alertmanager:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22receivers:
- name: 'custom-webhook'
webhook_configs:
- url: 'https://open.feishu.cn/open-apis/bot/v2/hook/your-webhook-id'
http_config:
headers:
Content-Type: 'application/json'
body: |
{
"msg_type": "interactive",
"card": {
"elements": [
{
"tag": "div",
"text": {
"content": "【{{ .Status | toUpper }}】{{ .CommonLabels.alertname }}",
"tag": "lark_md"
}
}
]
}
}自定义消息格式:
通过 JSON 或 YAML 格式定义消息内容,支持飞书的交互式卡片(如按钮、跳转链接)。